Many of us have been desperate for an iWork update for a long time, and Apple certainly delivered that this week. The updates to each of the apps haven’t been without controversy, as you’d expect, but the apps are now simpler, easier to use, and therefore have the foundations for a better suite of software. For those of us who keep track of these things, a major update to iWork is likely to come with a modification of the file formats for each application. And, indeed, that’s the case this year.
Why are file formats important? While it’s unlikely that applications will be wiped off the face of the earth, it might be important for you to ensure that any document created now is readable in the future. If your document is written using an app which saves files in a byzantine proprietary format, you may not be able to recover it in a few years’ time without having access to that same application.
A few weeks ago, an article by Charles Stross circulated which proclaimed that Microsoft Word must die. One of the reasons cited, among many, was its document format:
The .doc file format was also obfuscated, deliberately or intentionally: rather than a parseable document containing formatting and macro metadata, it was effectively a dump of the in-memory data structures used by word, with pointers to the subroutines that provided formatting or macro support. And “fast save” made the picture worse, by appending a journal of changes to the application’s in-memory state. To parse a .doc file you virtually have to write a mini-implementation of Microsoft Word. This isn’t a data file format: it’s a nightmare!
The iWork suite has typically been a little bit better at future readability. Sure, it’s no plain text format or HTML file, but it’s not too bad. To explore that in more detail, though, it’s necessary to travel back five years to iWork ’08. A document created in Pages was a package with the .pages extension, and it looked something like this:
buildHistoryVersion.plist
/Contents/
- PkgInfo
index.xml.gz
/QuickLook/
- Preview.pdf
- Thumbnail.jpg
/thumbs/
- PageCapThumbV2-1.tiff
- PageCapThumbV2-2.tiff
These files are pretty self-explanatory. There’s your usual OS X Package garbage in the way of the plist and /Contents/ directory, your QuickLook previews (in both a super-nice PDF format, and a super-compressed JPG file), and some thumbnails. The action takes place in a gzip-compressed XML file, which looks something like this:
<sf:section sf:name="Blank" sf:style="section-style-0"><sf:layout sf:style="layout-style-20"><sf:p sf:style="paragraph-style-32">This is an extremely <sf:span sf:style="SFWPCharacterStyle-7">exciting</sf:span> Pages document. It’s set in black 12-point Helvetica, which happens to be the default for Pages. <sf:span sf:style="SFWPCharacterStyle-8">This sentence is bold.</sf:span></sf:p></sf:layout></sf:section>
Please also note that I’m using Pages here, but the file types are similar across the iWork suite. A Pages document is the simplest representation of these file formats, however.
Please note that I’ve truncated about 250 KB of preceding XML definitions, and a little bit of end-of-document information.1 It’s not the easiest format to read, but it can be parsed without too much trouble. This format stayed very similar from the time Pages launched through iWork ’08, and Apple even documented it (PDF).
In 2009, iWork ’09 changed to a very slightly different format. The .pages file was really a .zip archive; unarchiving the file would produce a folder which was almost identical to the Pages ’08 hierarchy, except the XML file was not gzipped. The format of the XML file was unchanged, retaining backwards compatibility. In fact, it was possible to produce Pages ’08-compliant documents from Pages ’09 under the Save As… dialog:
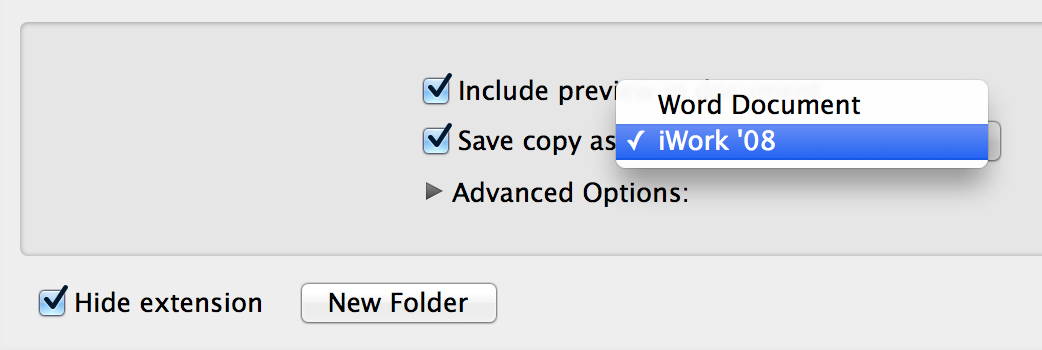
But this completely changes in the new versions of each iWork application. The new Pages format is, once again, a package, but it looks like this:
/Data/
(empty)
Index.zip
/Metadata/
- BuildVersionHistory.plist
- DocumentIdentifier
- Properties.plist
preview-micro.jpg
preview-web.jpg
preview.jpg
Looks pretty similar to the Pages ’08 format so far, right? Let’s unzip that Index.zip file:
/Index/
- AnnotationAuthorStorage.iwa
- CalculationEngine.iwa
- Document.iwa
- DocumentStylesheet.iwa
- Metadata.iwa
/Tables/
- DataList.iwa
- ThemeStylesheet.iwa
Despite appearances, this is exactly the same document as the Pages ’08 copy above. And .iwa files? I haven’t seen those in well over a decade.2
They’re not actually IBM Writing Assistant files, though. They appear as straight binary data of no known type:
$ file /Users/nickheer/Desktop/iWork-Docs/Pages13.pages/Index/Document.iwa
/Users/nickheer/Desktop/iWork-Docs/Pages13.pages/Index/Document.iwa: data
Just “data”. These files are pretty small, too: the smallest in this document, AnnotationAuthorStorage.iwa, is just 22 byes; the largest, ThemeStylesheet.iwa, is 32 KB. For comparison, the XML file in the Pages ’08 document is 294 KB (remember: it’s exactly the same document). Overall, though, the new Pages document is 112 KB, while the Pages ’08 version is 69 KB.
So, let’s crack these files open. If you try to open one of these .iwa files in a plain text editor, you’ll be greeted with this dialog:
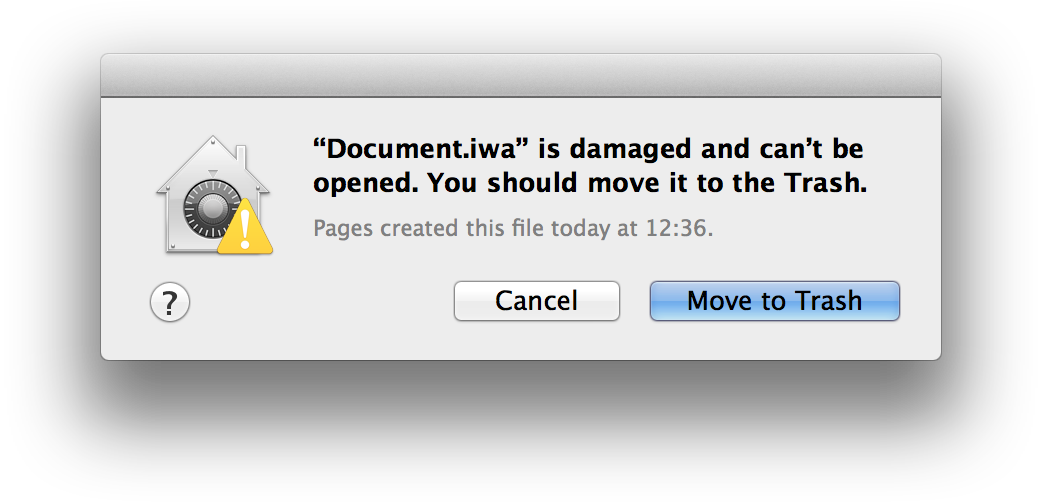
Despite this being a plain text editor (in this case, TextMate), it simply refuses to let me open this file. It’ll let me open images, but not this.
Fine. Let’s do this the old-fashioned way:
$ nano Document.iwa
It’s not exactly readable, but you can make out the document text and, for some reason, the fact that I have an Epson printer. I also tried a hex dump with the same file, which makes the following much clearer:
- Country and language settings (en_CA, en-GB)
- The paper size (“na-letter-fullbleed”)
- The template used (Blank)
Of course, that’s only the contents of the document itself, not its formatting. I did hex dumps of the rest of the files, producing very little of interest: the files are quite self-explanatory in their naming scheme, even if their contained data isn’t human-readable. And, obviously, this new format is not backwards-compatible.3
As I noted above, this matters for future compatibility. It’s unlikely that you’ll want to read your eighth-grade paper on Brazilian economics again, but legal contracts might need to be referenced in the future. Over time, we’ll likely create new and better ways of storing whatever data we create, but it should be possible for us to open things we’ve created in the past.
There’s the potential for lock-in with these files, too. While it’s no worse than Word’s lock-in, the ubiquity of Word has meant a lot of applications now read the .doc format, including Pages. But very few non-Pages applications read the Pages format, and with this new format, that’s unlikely to change.
These new applications are iMovie ’08 all over again. They’re fresh starts, and are not without their hiccups. I can see a lot of progress in these apps. I use Pages and Keynote extensively, and I’m thrilled that I don’t have to hunt for the Inspector.
I think the new file format is a regression, though. I would love to know the justification for these obfuscated data files, and what advantages they bring over the previous XML-based format. I’d love to be able to tell you what advantages they bring, but they’re unreadable. This isn’t yet a problem for end users, aside from the lack of backwards compatibility, but it might be in the future.
Last weekend, I finally got around to watching “Side By Side”, a documentary which explores the transition from film to digital video. There’s a part near the end where a few filmmakers discuss the importance of archival mediums, and they state that this is a bigger problem for digital video than film. However, they also point out that things which are important to us will be recoverable, should they be important enough. I entirely agree, but that’s not reason enough for yet more proprietary file formats to exist.
Update Oct. 28 A hot tip confirms that this new file format uses Google’s Protocol Buffers:
Protocol buffers are a flexible, efficient, automated mechanism for serializing structured data – think XML, but smaller, faster, and simpler. You define how you want your data to be structured once, then you can use special generated source code to easily write and read your structured data to and from a variety of data streams and using a variety of languages. You can even update your data structure without breaking deployed programs that are compiled against the “old” format.
Very clever. This supports the theories that this file format may support more efficient syncing. It’s not for nought.
-
And, yes, it’s entirely on one line. It turns out, by the way, if you open a single-line 250 KB XML document, it will make most text editors cry. Both TextMate and Coda hung when I tried opening this. ↥︎
-
I wasn’t alive when IBM Writing Assistant was released, but I briefly used it in the late nineties. I was a real cool kid, let me tell you. ↥︎
-
Pages ’09 files weren’t exactly backwards-compatible with Pages ’08, but if you unarchived the file, gzipped the XML file, and appended a
.pagesextension, you could approximate the Pages ’08 format enough that it would open it. It’s a hack, but I recall it working. However, I cannot check this out, as I don’t have a copy of Pages ’08 anywhere. ↥︎