Post galleries, share 24-hour stories, and browse feeds by following, For You, camera, or location.
The most obvious comparison is Instagram, but without videos. I have been trying Grain for several months; it is really fun and worth checking out despite an icon that is, charitably, difficult to love. It is built on AT Protocol, the same as Bluesky, so you can log in with the same credentials. Here is a recent photo set I posted.
If you are on an iOS 27 beta build, you will probably need the TestFlight version that includes a fix for a crashing bug.
Last December, Google sued SerpApi over scraping its search results, and now a court has granted SerpApi’s motion to dismiss the case. U.S. District Judge Yvonne Gonzalez Rogers dismissed these claims with leave to amend, giving Google 21 days to refile its complaint if it can demonstrate authorization from copyright owners.
You can see the court filing here (PDF) which basically says Google brought claims under Section 1201 of the Digital Millennium Copyright Act (DMCA), alleging SerpApi bypassed its anti-bot barrier (“SearchGuard”). However, Section 1201 only protects technological measures that restrict access to copyrighted works.
I had complicated feelings about this lawsuit because while I think there is little distinction between the web scraping activities of each party, and the effect of limiting SerpApi would be to reinforce Google’s illegal search monopoly, a win for SerpApi also seems to invalidate the meagre control website owners have over scraping. These restrictions are noticeable during normal web use and are quite frustrating. But without effective copyright reform, there really are few options for choosing whether you want your work to be incorporated into training data.
Reddit’s comparable lawsuit against SerpApi, among others, is ongoing.
People also asked if AI in Search would mean that people never click through to websites anymore.
Actually, as we’ve shared before, we continue to send billions of clicks to the web every day through Search. And we’ve designed our AI features in Search to connect people to websites. In fact, we’re now sending billions of clicks to websites every week through AI features in Search alone – and we’re just getting started.
The specific effects of Google’s A.I. search features is made murkier by all the other features the company has to answer queries immediately instead of sending them to an external website. Nevertheless, the claim that Google still sends “billions of clicks” is just another way of saying Google still has a monopoly on the world’s web searches. It is a substantially similar statement to the one Google issued a year ago, and something the company is only repeating because the New York Times asked for comment.
If only Google had some kind of dashboard or console with information about a website’s search performance.
Google even built out the AI performance reports in Search Console but excluded clicks. This is because Google is “continuing to work with website owners to understand what insights will be most helpful to inform their strategies” and Google doesn’t think those are clicks. Nope, because Google does not want us to see our click-through rates from AI Search features compared to traditional search features.
I am sure this is a mere oversight that Google will be eager to correct.
Apple and Klarna are partnering on a new “Apple Upgrade” program set to launch in the U.S. on Tuesday, July 28, according to Bloomberg’s Mark Gurman.
The program will allow you to finance most iPhone, iPad, Mac, and Apple Watch models, with a 24-month term for iPhones and Apple Watches and a 36-month term for iPads and Macs. Customers will be able to pay off the device early during the term, upgrade early to a newer device, or keep or return the existing device after the term.
In 2017, working with McKinsey, Apple said its supply chain would eventually become a closed loop, without specifying a timeframe or even a firm methodology for how it might do so. Perhaps encouraging people to treat devices as leased objects exchanged every few years gets closer to this goal, as Apple can capture a greater number of sold devices. (Be honest: how many of you have a bunch of old products sitting around unused? There is gold in them thar hills.)
Then again, the other thing I thought about is the rising cost of components, and the negative effect increasing prices could have on new purchases. Spreading the cost out over monthly payments might make some people feel less burdened by a dramatically pricier new Mac — something like what has happened with car sales. In the United States, for example, the most common way to purchase a new car is increasingly through financing, which divides the purchase price into monthly payments with added interest. Because the cost is divided up, it means manufacturers can increase prices and buyers can be pulled into longer and costlier payment plans.
Apple, of course, already has financing options for its new product purchases — Affirm in Canada, and a slew of options in the U.S. — as it has rapidly become a bank. If a large enough number of new Apple product buyers choose financing instead of outright purchases, it could incentivize more expensive products and longer payment plans. If you read that and got excited, you probably own lots of Apple stock.
If you believe Meta, its forthcoming Albertan data centre will be, at worst, unnoticeable to people across this province:
We pay the full costs of our data centers’ energy use so consumers aren’t negatively impacted, and fund new and upgraded infrastructure. We worked closely with Greenlight Limited Partnership, Altalink, Capitol Power, and the Alberta Electric System Operator to plan for and meet our energy needs years in advance of this data center coming online.
Sure sounds like the commitments of a stand-up corporate citizen. However, if you listen to the power companies, they tell a somewhat different story.
In its latest earnings call, [Capital Power’s] CEO Avik Dey predicted a “return to higher pricing” telling analysts that he couldn’t rule out prices of “$80 or $90” per megawatt hour of electricity by early 2028. By 2029, rival company TransAlta is predicting an average of $100 — more than triple the average price this year — a high not seen since the province’s 2021-2023 energy crisis.
Driving this increase is the province’s reliance on natural gas power, which cannot be built fast enough to accommodate data centre demand, according to Will Noel, a senior electricity analyst at the Pembina Institute. “In Canada and internationally, we’re seeing this huge crunch in gas turbine supply shortages,” he said. The province has also backed itself into a corner in terms of its options for alternatives. “Alberta has over the past couple of years really stifled the growth in its wind and solar.”
White reports this would increase the electricity costs to a typical household by “hundreds of dollars more per year”. However, as White caveats, these prices have precedent as recently as three years ago — and that undersells it. In 2022, electricity costs were as much as five times above current rates. Even without adjusting for inflation, we are currently paying less than we did from 2018–2020, and a tripling of the current rate would have a nominal cost similar to that of 2008. That is not to say this is good, but I think it is worthwhile seeing the “tripling” figure within the context of recent fluctuations.
Apple will make a rare conference appearance in Calgary next week, joining the inaugural Swift Rockies gathering for iOS developers at the Calgary Zoo.
Taking place July 22 and 23, Swift Rockies is a boutique, single-track conference created by Calgary-based iOS engineer Raman Singh. The independently organized event is capped at 180 attendees and designed to encourage closer interaction between speakers and developers through round-table seating and an intimate format.
[…] Even if the session being presented is one they offer globally, it’s fantastic to see Apple’s Developer Relations team again relating to developers outside of an Apple-managed event. That’s a welcome shift from the last few years that I was there (even pre-pandemic). My favorite part of being on that team was direct developer engagement. I hope it marks a return to form for WWDR.
Swift Rockies is sold out. According to the conference’s website, the presentation is open to any registered Apple developer regardless of whether they have a pass, though it does seem to be largely a recap of the biggest WWDC announcements. I have no idea if there is still space but, if you would like to go, you need to submit your request to Apple by midnight.
Also, if you are going to Swift Rockies and have never been to Calgary, send me a message and I can give you a couple of recommendations for things to do near the conference, if you want.
Meta Platforms faces trial in Tennessee on Monday over the state’s claims that Instagram’s design is to blame for a youth mental-health crisis, one of several trials in the coming weeks testing allegations that the company’s social media platforms were intentionally built to be addictive.
I imagine Meta will spend considerable time trying to nail down a definition of “addiction”. The lawsuit makes no attempt to define the term, though it does quote several internal Meta communications acknowledging this as an outcome of the company’s products.1 In a legal sense, this might be an important question.
The term, however, seems loaded: is Instagram really comparable to cigarettes? As a matter of practicality and ethics, I have personally found it more useful to think of this in terms of whether Instagram and its competitors are intended to be hypnotic and compelling beyond users’ comfort levels. I believe they are. A social media app today looks more like gambling, where you wager your time, than it does a continuation of real-world social experiences.
It is therefore too bad this lawsuit and others like it are exclusively related to the effects they have on children. I understand why, but I think we all need greater control over what we see. There are people I know whose TikTok feeds are absolutely full of A.I.-generated nonsense, often a mix of not-harmful trash and malicious information. This will not be solved by simply telling people of all ages to just say no to using these apps.
One hundred and forty years on from the Berne Convention, the basic principles of copyright remain the same, but GenAI poses a threat to authors different from anything that has existed before. Its novel technology is not only destabilizing what it means to reproduce works, but what it means to produce them.
This is a terrific and well-rounded exploration of copyright law and generative artificial intelligence from a non-U.S. perspective. That matters because the U.S. has a carve-out for “fair use” of copyrighted works, which is something generative A.I. companies are relying on for their defence of their unethical and maybe illegal practices. If it holds, it makes the rest of the world less desirable for A.I. development which, I fear, means it becomes a race to the bottom for all the countries that want a slice of this well-funded pie.
The AI music generation tool Suno scraped millions of songs and lyrics from YouTube Music, Deezer, and Genius, as well as from the stock music libraries Pond5, Jamendo, Freesound, the International Music Score Library Project, and podcasts via RSS feeds, according to a hacker who breached the company and shared data about Suno’s training libraries with 404 Media. The hacker was also able to access user information for hundreds of thousands of Suno’s customers, as well as Stripe payment information, they said.
Suno is fighting severallawsuits, including one filed by UMG in which it makes the argument its use is sufficiently transformative. But people have been prosecuted for the mere act of downloading hundreds to thousands of songs. This line of argument suggests to me that, beyond some astronomical number of downloads, it becomes entirely legal because no single song will be of much consequence.
A couple of days ago, Casey Liss took a break from arguing about temperature scales to tweak me about the recent passage of the Sunshine Protection Act by the House. The Act would make Daylight Saving Time permanent, something Casey knows I disapprove of. A similar bill passed the Senate a few years ago, and Donald Trump has said he will sign this one, so there’s a decent chance it’ll become law. Let’s see what will happen if it does.
Like many people, I was all ready to abolish DST until 2013, when I read Drang’s article advocating for the twice-yearly ritual of clock changing. I was converted.
Five years ago, the Albertan government asked voters whether we should “adopt year-round Daylight Saving Time, which is summer hours”. A bare majority, 50.2%, voted against it. So, of course, our government has adopted permanent DST, and we will not be turning our clocks back this November. This aligns with the practices of our neighbouring provinces.
The United States at least has the advantage of a large population living fairly far south. On the shortest day of the year, Los Angeles still sees nearly 10 hours of daylight and over 14 on the longest day. In somewhere as far north as Calgary, the difference in daylight hours is far greater — from under 8 hours in December to over 16 in June. That means the effects of permanent DST are highly acute. The sun will not rise here before 8:00 am from October 15 through February 8, with the latest sunrises at 9:39 am for several days in a row.
Theory is different from reality and perhaps my mind will be changed if it is still daylight after 5:00 pm on the shortest days of the year. I look forward to that. But this has been tried before — unsuccessfully — and I question why this time would be any different.
If you cannot get enough squircle talk, Michael Tsai has a whole roundup of different takes, some of which you may not have seen already.
Here is another thing: robbing icons of a variable for creative excellence and flexibility is just another form of context collapse. You know how Instagram and YouTube are host to professionals and amateurs alike? There are benefits to creating an impression of similar legitimacy, but the rigidity of social media platforms’ formats also collapses the difference between legitimate information and absolute nonsense.
Losing some of the artistry in an icon makes it more difficult to distinguish between legitimate and well-crafted Mac apps, and everything else. It is not a perfect proxy, to be sure, and there are some very nice squircle icons. But it is nevertheless an unfortunate change that makes apps of varying levels of quality look more similar.
Kashmir Hill, of the New York Times (gift link), learned about an A.I.-generated biography of her for sale on Amazon for $27. It is just one of many wholly-generated books available there:
Amazon does not mind if people hawk A.I.-generated books on its platform, unless they are truly and deeply terrible. “Charlie Kirk: An Inspiring Journey of Young Political Conservative and Activist Who Fights for America,” published in February 2025, became an Amazon best seller after Mr. Kirk was killed last September — which means it probably sold thousands of copies. But after dozens of scathing reviews called it “mind-numbing,” “a scam” and “a disgrace,” Amazon took it down.
Too bad about all the trees killed for this print-on-demand nonsense, though at least it fits with Amazon’s decline into one of the world’s biggest retailers of sketchy, counterfeit, and knock-off products.
Bryce Elder, on the Financial Times’ Alphaville blog:
Here’s paragraph one of the Morgan Stanley’s SpaceX initiation note:
With an ‘X of 1’ position in space infrastructure, we believe SpaceX can convert energy into intelligence at scale with optionality to monetize through a range of consumer and enterprise solutions for the next era of AI… the final frontier.
Today’s news that SpaceX has already started dipping below its IPO valuation reminded me of this piece. Remind me — is being compared to Shingy good?
At any rate, Morgan Stanley estimates that the combination of X and Grok will grow this year to generate only a little less revenue than Twitter did in 2021, its last full fiscal year as a public company. Fear not, investors, as the bank also says SpaceX will make $17 billion in “enterprise A.I.”, and then nearly triple that next year. I guess everyone wants to give money to the CSAM and misogynist fantasy generator for business.
In a newly published Apple Advertising Services policy, effective as of July 14, 2026, the iPhone maker shares its rules for advertising on Apple Maps. Notably, it prohibits the broad category of home services businesses, like plumbing, electrical, locksmith, HVAC, pest control, roofing, and general contracting services, among others.
If Apple is interested in updating its advertising policy further, I suggest none. I spent lots of money on its nominally premium products, and I pay a monthly fee to use the company’s services. Alas, here we are.
Apple is also prohibiting ads for cryptocurrency ATMs. Also, there is this:
2.7.2 Ad content that directly or indirectly promotes or facilitates the sale of products or services that compete with Apple hardware products (e.g., mobile phones/smartphones, tablets, notebook/desktop computers, and smart watches) is reviewed on a case-by-case basis.
Eric Benjamin Seufert, who writes Mobile Dev Memo, noticed the phrase “on the relevant Apple software applications or
Apple devices” has been changed to remove references to Apple-specific devices or software:
The new language could simply accommodate the availability of Apple-owned services on the web and through third-party devices and operating systems; the Apple TV app, for instance, is available on smart TVs, streaming devices, and game consoles. But the addition of “other properties” is conspicuously broad and appears to give Apple the contractual latitude to distribute ads beyond its own services entirely. This would allow for a material expansion of the company’s advertising surface area.
Apple Maps is also available on the web and is used by DuckDuckGo, so this could simply be covering that inevitable broader placement. But the reality is that Apple is now operating an advertising business, and putting more ads in more places is one way to make the numbers go up. Not the user satisfaction numbers, of course — I cannot imagine a single user who wants more ads in their life, unless they own shares in this company. But it will print money at no cost, and that is what the people running a huge corporation with little competition want to do. It was not inevitable until Apple made it so by opening the door.
With last year’s release of MacOS 26 (Tahoe), Apple made a mess of app icons. In the first betas of MacOS 27 (Golden Gate), however, there are signs of a turnaround. We’re urging Apple to continue making improvements, by restoring the ability for MacOS app icons to have distinct shapes.
Kafasis reignited my simmering frustration with the mandated squircle in MacOS. My Dock contains three of the apps shown in the collection in this post: MarsEdit, NetNewsWire, and Sketch. I like their current more-uniform icons fine enough, but they are less distinguished than the ones these applications used to have.
The shape of apps is a squircle. And it has been proven to work for everyone. Companies can use their logo as an app icon. Designers can create something specifically for the platform. And both of these get to look like an app. Whether people consider the squircle a container or a canvas, this uniform appearance communicates its function: a squircle represents an app, just like how a piece of paper represents a digital document, or a folder represents, well, a folder.
Semantically, there’s something really beautiful about that. As an icon designer, I appreciate that different types of things have visual distinction.
Mantia touches on all the pragmatic reasons to unify the shape of icons in an operating system, all of which I have considered, and then drops the above paragraphs — and things started to make more sense to me. This is a different way to think about it. This is not a situation where a cleaner looks like a zesty beverage with toxic consequences. The shared general function of these icons does help communicate something and makes them less ambiguous in that sense.
But a broad category of functionality is only part of the story of an icon and — with respect to Mantia’s long and illustrious history of work in this area, and that of co-Parakeeter Luka Grafera — taking away a difference of shape also limits what an icon can communicate. It may not be a cleaning product that looks and is packaged like juice, but imagine if every consumable liquid was in identical bottles with only a different label. You might go for something refreshing after a workout and end up drinking soup. Sure, you can argue the label for a beverage should not look similar to the one for soup, but the two would be far easier to distinguish if they were not in the same package.
I still think constraining designers to a singular shape, while more clearly defining specific objects as apps, has made it harder to distinguish between them, particularly when combined with the glassy and contrast-killing layer effects of Tahoe. Happily, though not retreating on the squircle, the shapes within icons in MacOS Golden Gate are at least more clearly defined.
A friend pointed me to this option in Meta Accounts Center called “Activity from other businesses”, which shows “activity sent from other businesses or organizations to show you relevant content.” Their main help page doesn’t even work in my region.
If you dig around in your Meta account privacy settings, you can turn this feature off. While you are there, though, you might take a scroll through the audience-based advertising list. These are companies that have, most often for me, “uploaded or used a list” of email addresses or phone numbers. In my case, this is hundreds of businesses — some of which I recognize or can see why they would have my contact information, and many of which I have never heard of. Advertisers are supposed to have permission to use this information, of course, but there is basically no way for me to confirm whether I gave permission or report that I did not. Restricting further use is also comically unfriendly: it is a button two levels deep and, for all but the first four advertisers, you must click a “See more” button each time to display the full list.
Update:Rodrigo Ghedin counts four separate privacy-hostile things Meta has done or is rumoured to be working on since the beginning of June.
One lie that companies have been telling local municipalities is that if they greenlight a massive local AI data center, it will immediately bring a flood of savvy innovators to your podunk-ass town.
The promotional materials for Kevin O’Leary’s still hypothetical “data centre park” imagine a futuristic campus full of bright young minds doing complicated A.I. stuff on-site in north-central Alberta. But why would they be there — fifty kilometres from the nearest city and 500 kilometres from Edmonton, the nearest major city? Why would they not be in Vancouver, or Silicon Valley, or anywhere else with an internet connection?
Also:
These companies aren’t coincidentally aiming construction at states and municipalities that are too broken and corrupted to put up meaningful regulatory opposition. […]
The fixer — Ellis called him Ray and won’t reveal his name — met him in North London near Hampstead Heath for coffee and cakes. When it came time to discuss business, to avoid being overheard, they strolled into the park.
Ray had brought Ellis a few jobs before. But this job, he warned, was of an entirely different order. As Ellis claims in “The Art of Robbery,” a self-published memoir written after his release from prison, he eventually learned that Ray had been contacted by a consultant employed by “some influential bankers from America.” The bankers “were involved in prime mortgages” and had “circumnavigated” certain regulations. Damning evidence of these circumnavigations could be found in banking files held in the King’s Cross area in a giant building known as a data center.
This is a dramatic story, and one I think should be read with a heavy dose of skepticism. It seems that most of the criminal details have been shared by Ellis. For a start, the claim that some bankers ostensibly contracted with “Ray” is just a little too perfect for a recession-era tale. These bankers are pretty much universally loathed, and this justification makes this theft seem more palatable than a simple financial motive. For example, there was a similar data centre theft in October 2006, which would be unrelated to the lending crisis in the following years.
Another problem is that Rich says crimes like these are covered-up in part by a data centre operator because they are loathe to “admit to flaws in its security, [which] would only encourage additional attacks and scare away its clients”. Therefore, the lack of evidence for the specific circumstances of this crime is supposed to be a buttress for its likelihood, not a weakness, which is not reassuring.
The story of the theft was, as far as I can tell, broken by Here is the City, then a gossipy financial news site:
The data center itself is thought to be used by a number of companies, including JPMorgan, which is believed to have told staff that some of its systems could be off-line for parts of the day today as a result of the theft. Fortunately the thieves are thought to have got away with just the computer hardware, and not any sensitive information which may also have been stored at the facility.
Reports circulating on the Internet last week that JPMorgan, a customer of Verizon Business, had been affected by the burglary were incorrect, according to a source at the investment bank. There has been no loss of service or data, said the source.
On the one hand, of course all these parties tried to cover this up. The reading-between-the-lines story implied by these early reports and Rich’s telling is that some banking higher-ups, perhaps from JPMorgan, wanted to cover up some crimes, and denying any meaningful effect is just more cover-up. But little of this is substantiated by contemporary or current reporting — which is, of course, the whole problem with using a lack of evidence as the foundation for a story.
Rich, in the Times:
“The banks knew they were sending mortgages to people who couldn’t pay back,” he says today. “That’s what broke the whole system. That was the big con.” Ellis remains convinced that the bankers who paid for the Verizon job wanted to destroy evidence of their involvement in fraudulent subprime mortgages — the inside information that Ellis received about the data center, he believes, “would have had to come from the top” — but he can’t prove it. He never saw what was on the servers.
“Our job was to get the motherboards,” he says. “We were paid quite handsomely. Whatever happened after that was none of our concern.”
In contemporaneousreports, the Metropolitan Police noted the theft of motherboards and processors. But if these bankers wanted to cover up their fraudulent practices, surely the hard drives would have been the target, right? In Rich’s version, entire servers were taken, so perhaps this is just a misunderstanding.
This story smells fishy. I believe the theft happened, of course, and Ellis’ involvement, but I am not as convinced this had anything to do with covering up some white collar crime. (By the way, the Guardian in 2018 published an interview with Ellis about the interesting prison where he was transferred and which led to his rehabilitation.)
The heist element is only about half of Rich’s story; much of it is a discussion about data centre secrecy:
The public fogginess about data centers is not an accident. It is the product of a willful strategy by the world’s largest tech corporations, whose business models rest on the public assumption that the internet, and all the data it holds, is as immaterial as air — or as a cloud, to borrow the metaphor commonly used to describe the sum of information stored on servers. As the digital-media scholar Tung-Hui Hu writes in “A Prehistory of the Cloud,” the cloud “hides its physical location by design.”
[…]
It was a lot easier to defend data when people didn’t know it existed. The more people learn about data centers, the more they hate them. […]
If you read a website like this one, you were probably aware that data centres were commonplace twenty or more years ago. Like the one near King’s Cross, some were hidden in plain sight, while others were purpose-built facilities that look like hangars stuffed with servers. But the A.I. boom has meant rapid increases in the speed, scale, and quantity of data centres. People quickly learned not only of their existence, but how much pressure they put on local resources. Tech companies, it seemed, were caught by surprise; and as someone who spends a lot of time immersed in this world, so was I.
Much of the consternation I have seen in more general audiences has been about data centres in general. People simply were not aware that Amazon has warehouses full of products, and other warehouses full of computers. As Rich writes, this is deliberate, for business secrecy reasons, security, and environmental costs. But, also, I think some of that unawareness is because of just how boring it is. If nobody wants to know hidden information, is it really a secret? It only became one when the information these companies were hiding had real-life effects.
It does seem that public awareness is putting pressure on corporations to improve data centres and make them more efficient. But that is not a standard. New data centres are powered by petroleum with a pinky promise of renewable offsets. In some regressive regions, like Alberta, new power plants for data centres must be powered by methane gas. In a further complication, Meta’s proposed data centre is scheduled to be completed before the power plant is ready, meaning it will be dependent on existing grid power for perhaps years. Meta’s is just one of the data centres proposed for Alberta. Another one, a gigawatt cluster, would also require a dedicated gas-fired power plant, while Kevin O’Leary’s questionable project is supposed to require over three times the combined power of those other two.
For years, the tech industry told us we did not need to have much concern for how digital products and services worked, and many of us did not bother to find out. But it turns out the demands of our email and Netflix subscription were comparatively easy to hide. At the very least, what we ought to demand from projects with the scale and ambition of these data centres is open disclosure of their power consumption, water use, and emissions.
But we ought to demand more than the bare minimum. Transparency does as much good as a big banner reading we are destroying the planet but we are also creating a lot of value for shareholders. When a single data centre is projected to use about as much power as the entire city of Calgary is currently — Enmax says 1,260 megawatts as of writing — we should have a say in whether that makes sense. A.I. remains a thing that is happening to us rather than with or for us. It is built on assuming consent and asking forgiveness, which has more-or-less worked for the industry and gave it way too much confidence. Tech companies could have spent decades being better corporate citizens. Data centres are just one part, but they are representative of the difference between the stories told by tech companies and the things we can actually know.
Meta, in a press release called “Meta’s A.I. Glasses: Your Questions Answered”:
Can’t people just cover up or disable the LED?
The camera is disabled when people try to do this. Beginning with our second generation of glasses, the camera is automatically disabled if we detect that the capture LED has been blocked. No photos or videos can be taken until we detect that the light is unblocked.
Since the introduction of this safeguard, we’ve seen some people go beyond using tape to sophisticated efforts to modify or destroy the capture LED. We are continuously improving our ability to detect tampering, and now we’re updating the glasses to disable the camera if they detect the LED was physically tampered with or destroyed. No other kind of camera has done this and we’re proud to lead the industry forward.
Meta is not being entirely honest here. For many, many years, Apple’s laptops have contained a camera indicator light with among the highest security protections possible. Over ten years ago, iSight cameras were not adequately secured. I cannot find a more recent example showing a similar vulnerability, at least suggesting a better level of protection in today’s cameras. Other computers also have built-in cameras with in-use indicators, with various approaches to security, some of which have vulnerabilities. In general, though, it is not new for an indicator light to resist tampering as long as the camera remains functional.
What is different is the threat. Cameras built into computers need protection mostly from remote attacks, while Meta’s glasses need protection from an owner deliberately altering them. Meta is selling creep glasses and hoping it can outsmart everyone buying them — and that the rest of us similarly trust Meta to protect our privacy.
But it gets better! Meta’s planning a new version of the glasses that records continuously! [FT, archive]
a new hardware line of smart glasses that would continuously record audio while taking photos every few seconds.
And they won’t have a recording light. […]
This product is still rumoured, and perhaps the shipping version will have some kind of external recording indicator. But given the way Meta would intend a device like this to be used, I doubt it will, otherwise it would be indicating basically all the time.
Meta is in the business of asking for forgiveness instead of seeking permission. It will release these regardless of public approval, and with the belief it can control how that continuous recording is used. But determined people will surely find workarounds and vulnerabilities, and Meta surely believes it can trust itself to fix them. But I do not. Meta has not earned the right to ship anything like this without incurring deep suspicion about the product and anyone using it.
ShinyHunters published the [Madison Square Garden] data on Tuesday. The full file download is nearly 45GB. A spokesperson of the group sent 404 Media a smaller sample of the data. One file includes what appear to be emails sent by customers to MSG and sometimes MSG’s response. One email is a man complaining about potentially being flagged by MSG’s facial recognition systems (MSG owner Jim Dolan has long spied on people inside his arenas, with MSG deploying various surveillance technologies, WIRED reported.)
The talent database also tracks some celebrities’ race, gender identity, and sexual orientation; 93 entries are marked as “LGBTQIA.” Why MSG felt the need to label Ricky Martin or Phoebe Bridgers or Geese’s Emily Green in this way is unclear.
“I’ve never met James Dolan. I don’t know the higher-up leadership at Madison Square Garden. But, like, there does seem to be a bit of a pattern here,” says Evan Greer, director of the digital rights group Fight for the Future, citing WIRED’s reporting on the Garden’s minute-by-minute surveillance of a trans woman. “They just seem overly interested in queer and trans people in their venue,” Greer adds.
I cannot imagine what it would be like to be the person who put this together, stepped back from their computer, and thought yes, this seems fine. How surveilling people like this is not criminal, I have no idea.
Update: Madison Square Garden is suing Wired for its story, calling it false and “with reckless disregard for the truth” while also acknowledging that, according to Travis Bland at Consequence, it kept “information on celebrities’ sexual orientations” — but for good reasons. Bland’s article appears to have a link to the lawsuit, but it is a document in Madison Square Garden’s internal SharePoint, so it is password-protected. If you are interested in reading the suit, there is a valid link in the press release (PDF) announcing this legal action.
You know what I miss that cars often had up until the ’90s or so, and are almost extinct today? Badges. Not the usual make/model badges, though, we still have plenty of those, I mean the highly-specific feature badges that cars used to proudly display. Actually, not even just features — also technical details.
Torchinsky’s ideas for modern versions of this are very good.
Apple on Friday sued OpenAI in federal court in Northern California, alleging trade secret theft, saying that the artificial intelligence lab took the iPhone maker’s intellectual property in order to develop its own consumer hardware.
The docket is on CourtListener, along with Apple’s complaint (PDF). What is immediately notable about this whole thing is the myriad conflicts of interest. Apple, of course, has a current partnership with OpenAI to power Apple Intelligence features, something repeatedly mentioned on the previous version of its marketing webpage, and conspicuously absent on the current one.
But the history runs far deeper. Among the defendants in the suit is io Products — do not blame me for that capitalization choice — founded by Jony Ive and acquired by OpenAI last May. Total mentions of “Ive” in the body of this lawsuit? Zero. Also, one of the investors in Ive’s company was Emerson Collective, founded by Laurene Powell Jobs, and which now has equity in OpenAI. Neither Emerson nor Powell Jobs are defendants.
In May, Kalley Huang of the New York Times reported OpenAI was “weighing legal action such as sending Apple a notice claiming breach of contract” because it felt Apple was not doing enough to promote ChatGPT through its Apple Intelligence integration. I would be surprised if that modest tie-in exists for much longer. When you update to Siri A.I. in iOS 27, for example, ChatGPT is turned off by default, though it is possible to re-enable it. It is also listed in Settings under an “Extension” sub-section — currently singular, though perhaps not at some point in the future.
The X/Twitter account IRIS C2 (@C2IRIS) has gained more than 4,000 followers since its creation in January 2025, posting frequently about security vulnerabilities, AI and software exploits. IRIS C2 says it is a company in McLean, Va. that sells offensive cybersecurity capabilities.
[…]
A search on the Arlington, Va. address listed in the incorporation records for Calvexa Group LLC finds the property is occupied by Jack Burkman, the 60-year-old founder and managing partner of the lobbying firm Burkman & Associates. When approached with questions about IRIS C2, Burkman referred further inquiries to his longtime associate, 28-year-old Jacob Wohl.
Now there are a couple of names I have not heard in a while, probably because their previous scheme was established under fake names. In an interview with Krebs, Wohl claims to “know more about tech than anyone”, which sounds about as delusional as anything else he has ever said.
Anyway, if you want to risk getting scammed, the company claims to be hiring.
Once complete, our Sturgeon County data center will represent an investment of more than CAD $13 billion. We anticipate approximately 3,000 construction workers will be onsite at the peak of construction, and the data center will support more than 300 operational jobs.
[…]
As with all of our data centers, this data center’s electricity use will be matched with 100% clean and renewable energy.
Last week, Calgary-based Pembina Pipelines, Morgan Stanley Infrastructure Partners and Kineticor announced they will build a new 932-megawatt (MW) gas-fired power generation facility in Sturgeon County to power the data centre, although they didn’t identify a customer at the time.
Chalk up another questionable outcome for the environmental record. Meta makes a lot of big promises in this news release and in an interview for Varcoe’s column, but I question whether the company can be adequately monitored, particularly by this provincial government.
Langley offers a prediction: In less than 10 years, Flock’s cameras, airborne and fixed, will eradicate almost all crime in the U.S.
That would be Flock Safety CEO (and co-founder) Garrett Langley speaking to Thomas Brewster of Forbes. Flock Safety has grown a lot over the past few years, following paths paved by Amazon’s doorbell surveillance camera acquisition, Ring, and other upstarts in the public/private surveillance mesh network field.
Ring founder Jamie Siminoff made a similarly unsubstantiated claim to Jennifer Pattison Tuohy of the Verge. The reality, however, is that cameras from companies like Flock and Ring are giving a sheen of authority to false accusations made by law enforcement.
In September, for example, Chrisanna Elser of Colorado was falsely accused of theft by a police officer using Flock’s cameras. The entire exchange was recorded on her doorbell camera. 404 Mediaobtained body camera footage which showed the officer refused to see exonerating evidence, in the form of cameras on her Rivian truck and a Ring camera at her tailor’s house. This is just a mass surveillance race to the bottom. The officer in question was required to complete additional training for politeness as a result.
On an otherwise normal Sunday afternoon in late June, I’d decided to take the $155,000 Range Rover I was testing that week out to run some errands with my wife. Little did I know that choice would complete a technological chain linking surveillance cameras, AI, and law enforcement that led to me and my wife being surrounded by police, hands on their guns, in a Kohl’s parking lot in suburban Minnesota.
Without spoiling this story too much, this was the result of a typo that affected several more vehicles than the one Feder was driving.
Although Flock cameras are often referred to as license plate readers, that’s reductive. Reading license plates is their primary task, but they can be used to track just about anyone or anything. Even without a license plate, law enforcement officers can search for things such as, hypothetically, “green sedan with American flag bumper sticker,” or, “pickup truck with paint scratches on left side and dirt bike in truck bed.” Reducing Flock ALPRs to license plate readers is a bit like calling your own eyes “Engadget article readers” simply because that’s what you’re using them for at this particular moment. The company also offers AI surveillance cameras which do track individuals.
I keep thinking about Elser’s story. The way she was implicated was thanks to a network of cameras surveilling her every public move, and the way she was exonerated was because of documentary evidence from a bunch of cameras surveilling her every public move. It was not very long ago that U.S. media was freaking outabout thenumber of CCTV cameras in the U.K., but the U.S. has quickly caught up. There are hundreds across Canada, too.
To state the obvious, this ubiquitous surveillance has not eradicated crime. What it has done is give police the false confidence to accuse random people of crimes they did not commit. It has also allowed police to stalk people for personal reasons, despite major investors Andreessen Horowitz claiming critics “overlook the vigilant protections in place to ensure that Flock cannot be used for surveillance or to violate privacy”. That is nonsense — perhaps a lie, similar to those told by Flock. But it is not a lie any greater than the idea that we can eradicate crime if we just have more cameras with A.I. features.
We’re continuing to make Google Earth on web and mobile (Android | iOS) the best place for people to get helpful geospatial insights. While you can continue using the legacy Google Earth Pro desktop app, it will no longer be available for new downloads beginning on June 25, 2027. We encourage using web and mobile for the best Google Earth experience.
This is a two-factor loss: the MacOS app is Intel-based and, thus, will no longer be supported by the system come next year.
Discontinuing Google Earth desktop does not come unexpected, but it’s terrible news. The web tool is utterly useless for me and many geo folk.
There’ll be workarounds for most features, but not for easy 3D view of historical imagery and for sharing placemarks.
Carlos Moffat, faculty at the University of Delaware:
Still one of the most approachable and efficient tools for planning fieldwork. I used GEarth in our latest Antarctic cruise just a few months ago.
On the Google Earth community thread, you will find comments from people with all sorts of interesting use cases for the desktop app. I opened the web version today to see if it supports my limited use cases — it does — and I was greeted by a dialog advertising Gemini features, of course.
I am a tiny bit sorry for all the links I am posting regarding age gating. As I have written before, it is something I am still trying to work out for myself. After all, it seems straightforward why age verification is an easy way to reduce the risks to children of today’s platforms, the operators of which marketed their products directly to kids. But the trade-offs are numerous, whether from a predominantly U.S.-centric view of individual freedoms, or from the way such restrictions fail to address product safety concerns.
In practice, of course, a social media ban would be widely circumvented. If we think the internet is bad for teenagers now, imagine a world in which all online access is illicit. Social platforms would have a new defence against online harms against that group: they’re just not meant to be there.
Provided Facebook, X, TikTok or whoever could show it had some legally compliant age verification system, harm befalling a teenager wouldn’t be their fault. They weren’t supposed to be there, after all. Instead of being the negligent owners of a space marketed to teens, they’re the blameless victims of trespass.
Age gates are such a procedural and mediocre response. Instead of reining in whatever broader risks may be invented or exacerbated by these companies’ products — and, in particular, the unique problems of each — we are throwing up our hands and pretending it is all too complicated.
Meta Chief Executive Mark Zuckerberg acknowledged shortcomings in the company’s sweeping restructuring at an internal town hall on Thursday, saying the systems known as AI agents had not progressed as quickly as he had expected, according to a recording heard by Reuters.
[…]
In retrospect, he said, the “trajectory of the agentic development over at least the last four months hasn’t really accelerated in the way that we expected,” and that the company’s bets on the new structure “haven’t come to fruition yet.” Zuckerberg was referring to AI agents, automated systems that can execute tasks on behalf of a user.
A quintessentially Zuckerbergian premise: he pivots the whole company around whatever is the new thing, says oops, then reminds himself that nothing really matters as long as people keep looking at ads on Instagram.
For all Meta’s power and its massive base of users and ad buyers, the company’s YouTube channels are fascinating places. The main channel has a bunch of promo videos for the headlining products Meta wants people to associate with a world-changing company. There are corporate presentations hosted by Zuckerberg, ads for A.I. and glasses products, and little behind-the-scenes things, and all of them have hundreds-of-thousands to millions of views. That is what you would expect for an account with 456,000 subscribers and a household name. It really wants you to believe its leadership is made of visionary stuff.
But the way it actually makes its money — advertising — is nowhere to be found on that channel. For that, you need to go to the Meta for Business channel, which has a respectable 181,000 subscribers and lots of tips for how to use the company’s ad tools more effectively. But the view counts on those videos are, frankly, terrible. Most are in the dozens-to-hundreds; again, this is a channel with enough subscribers to get a famous silver plaque.
Meta can tell the world it is a revolutionary company while being internally honest about what it actually does. Many companies do that. But it is fairly troubling that Meta seemingly tricked itself into believing the external picture it paints.
Following Australia’s move in late 2025, Indonesia became the first non-Western country to announce restrictions on social media access for users under 16. Rules unveiled on March 6 require platforms such as TikTok, Instagram, YouTube and Roblox to introduce age verification checks and remove underage accounts. The restrictions were supposed to take effect on March 28, but enforcement has been patchy, with tech companies largely ignoring the requirements and underage users continuing to access social media simply by lying about their ages.
As Michael Geist put it recently, “the better the privacy protection, the less effective the ban”.
As of 2026-07-28, this project is archived. It’s been a fun challenge to develop a syncing client, but unfortunately, I find too little time to invest in Maestral these days. I’ve also moved away from using Dropbox myself.
Maestral will still remain usable in the medium term, but will no longer be actively maintained or receive updates.
This is a bummer — understandable, but a bummer nevertheless. The official Dropbox app is hundreds of megabytes because, of course, it is a website masquerading as a native application with the help of Electron. Maestral is comparatively svelte, has a low memory footprint, and does not use Apple’s questionable File Provider API.
I use Dropbox only for some relatively basic but necessary things, like hosting PDFs for this very website, which is why Maestral has been the perfect client for me. It is a testament to the effect of a good third-party app that I have stuck with Dropbox despite its corporate-focused strategy pivot.
Anyway, many thanks to Schott for creating such a good little utility. Maestral is open source so I have hope somebody will take the baton.
AI agents are agents of the person or organization that deploys them—and should be treated by the law as such. If a company hired human writers to write its summaries, that company would be liable for inaccuracies in those summaries. If a company’s human agent signed contracts in the company’s name, that company would be bound by those contracts. And if a doctor gave dangerously wrong medical advice, they would be liable for malpractice.
To allow businesses to hide behind the excuse of faulty AI in those same circumstances would be a massive handout to companies, and would introduce disastrous incentives for corporate misbehavior. Why hire human writers, lawyers or doctors when AIs are not only cheaper, but also absolve employers whenever they make a mistake?
In his video essay nominally about artificial intelligence, economist Cahal Moran repeatedly references the book “The Unaccountability Machine” by Dan Davies. I am only a couple of chapters in, but I think I am going to get a lot out of it, and I feel confident you should check it out from your local library.
If you know of a cool, weird, eye-opening, or simply interesting web-based thing launched between July 2025 and this month, consider nominating it for the award.
Satya Nadella at Microsoft’s Build conference this year:
Perhaps the most important design criteria for us is: ‘how do we earn the permission from the communities in which we are building these data centres?’
That’s where these principles ground us and focus us. How do we ensure that the D.C.s do not increase the electricity prices? Making sure that we are replenishing all our water use. Creating jobs in the local communities for the local residents. Adding to the tax base. […]
Kate Brandt, chief sustainability officer at Google:
While we remain deeply committed to sustainability, reaching our climate moonshots is getting harder. It takes energy and resources to support the growing demand for AI that powers businesses and the tools we use every day. Like everyone in our industry, we experienced a surge in electricity demand last year. Our AI infrastructure buildout is accelerating faster than the grid is decarbonizing, and long waits to connect to the grid, fragmented markets, supply chain delays, and regulatory bottlenecks continue to slow down new carbon-free energy from coming online. We’re working within energy systems that simply aren’t clean enough or flexible enough yet.
Microsoft, Google and Amazon are among the tech companies spending an estimated $1 trillion on AI infrastructure this year and last. In some regions, they are using far more water than they report, depending on how data centers are powered. And their water consumption is projected to grow rapidly in coming years.
These companies produce annual sustainability reports that include water use at their data centers. But among this group of titans, only Meta tallies water used at the power stations that feed them electricity, in addition to the water used on-site.
Google’s power consumption rose by 7 TWh between 2023 and 2024. That was bad. But it rose by a whopping 12 TWh between 2024 and 2025, almost double last year’s increase. Google’s power consumption isn’t just growing — the rate at which it is growing is growing. We have a word for this: exponential growth.
Every time I look at this chart I have to go and double check every single Google number, because it just looks so ridiculous.
In their environmental reports (all PDF links), Apple, Google, Meta, and Microsoft all mention carbon capture or direct air capture as one strategy for minimizing the impact of their emissions. Reporters for Heated and ProPublica jointly published a look at carbon capture technologies. They found that carbon capture remains a basically theoretical technology despite decades of promotion. Meanwhile, solar energy installations have dramatically outpaced even the most optimistic projections.
Despite the technical difficulties, there are photographs of Canada in the 1860s — including one taken of the historic moment the proclamation of Confederation was read out at Market Square, Kingston, Ontario.
I had no idea there was a photo taken when this proclamation was read.
When Apple announced Siri A.I. would not be available on E.U. iPhones or iPads at launch, it said:
Given the serious risks to users, Apple designed a solution called Trusted System Agent — an intermediary that would allow virtual assistants to safely access the same features and capabilities as Siri AI for devices in the EU. Apple also shared a plan to launch Siri AI in the EU while gradually rolling out this new solution over an 18-month period. The European Commission said no. In fact, the European Commission did not agree to any of Apple’s proposals.
I noted the curious mix between this pitch and Apple’s claim that — translated from French — “none of its engineers are currently working on solutions to open Siri A.I. to the competition”. I interpreted this to mean Apple was no longer working on the Agent idea for giving third-party A.I. systems comparable access. On reflection, I am more confused: is Apple throwing a red herring into the mix by claiming it is not giving competitors access to Siri A.I., something which I do not think the E.U. was asking for?
In that same post, I also reflected on how it was “refreshing to see Apple and the European Commission arguing in public and on the record instead of by leaking information to the Financial Times“.
A commission official said its contact with Apple on the idea was limited, and that it lacked a concrete proposal or details on how such an agent would work beyond the general concept. They said Apple “focused on obtaining a green light to delay the compliance”.
By contrast, the official said the commission’s process with Google after changes it made to its Android operating system led to a formal consultation on how the company could comply with the DMA and avoid massive fines.
To the extent Apple is not getting sufficient information about the validity of its proposals, the Commission is saying that is entirely Apple’s fault — obviously. I bet Apple thinks it is all the Commission’s fault, too. The DMA has been in effect for nearly four years and there is no reason why either party should be having so much difficulty with this proposal stage. Either the Commission is mischaracterizing Apple’s engagement, or Apple’s representatives need to be far better prepared.
One more thing I wrote last month:
Given Apple’s self-imposed problems with Apple Intelligence since WWDC 2024, I question whether many people in Europe will find this particularly disruptive or upsetting, however.
Well, according to Acton and Moens, I was quite wrong:
The dispute triggered a fierce public backlash against the commission, with European officials reporting hundreds of emails from consumers accusing Brussels of depriving Europeans of a new technology.
One EU official said that a commission spokesperson had received a stream of abusive messages, including several death threats.
A.I. really is breaking brains. Shameful behaviour.
As consumer preferences and the broader entertainment industry continue to shift away from physical discs to digital, physical game disc production for all new games releasing on PlayStation consoles will be discontinued starting January 2028. Following this date, new games will be available on PlayStation Store and at retailers in digital formats only. […]
After nearly two decades of supporting the PS3 console generation, we wanted to let you know we will be closing the PlayStation Store on PS3, as well as on PS Vita. […]
Incredibly, these announcements were made on the very same day, as if to illustrate the fragility and centralized control of the digital-only distribution Sony says is the new standard. At least physical versions of PS3 and Vita games will continue to function. Remember how, in 2023, Sony said it would yank access to media purchased by users because Sony did not renew its license with Discovery? If we cannot actually own something, I find it difficult to believe an unpaid reproduction of that thing is actually tantamount to theft.
Update: Just this week, Sony said it would remove hundreds more titles from users’ accounts in the U.K. due to its licensing with StudioCanal expiring. (Also, Sony and Discovery struck a new agreement in 2023.)
So what, I can hear you thinking. I don’t know or care what anyons are, or how gallium arsenide works. Me neither! The interesting part of this story for me is that Microsoft — a company that has a market value of $2.7 trillion and almost single-handedly created the personal computing industry — has repeatedly claimed that its Majorana processor uses these particles, and that its new version is a thousand times more reliable, and yet some other theoretical physicists have called BS on these claims, not once but several times. In other words, Microsoft keeps putting out press releases saying it has done this, and that it will build a working quantum computer using said particles within the next three years, and a number of prominent members of the industry keep saying that the company and its research scientists are full of you-know-what.
It is fascinating to see academics call out one of the world’s most valuable companies for making claims that are “perhaps even ‘fraudulent’”.
We’ve discovered vulnerabilities in Hide My Email that allow attackers to discover the meant-to-be-hidden address behind a Hide My Email address. We reported the issue to Apple over a year ago, and as of June 30, 2026, it still hasn’t been fixed. About a month ago, we realized that the vulnerabilities’ severity and scope are greater than we initially thought. […]
Apple replied — twice — that it had fixed these vulnerabilities, but Joseph Cox of 404 Media was able to reproduce the problem as recently as earlier this week. Very few details are available right now. I have seen speculation that the original email address is revealed when someone replies using their hidden email address, but the impression I get from Cox’s reporting is that no user interaction is necessary:
To test the issue I generated a new Hide My Email address and provided it to Murphy. Around five minutes later, he replied with my real email address linked to my Apple account which was supposed to be hidden.
I am also unclear about how, as of May, the EasyOptOuts guys found the “vulnerability may have greater severity and scope” than initially reported. Ominous, though.
Also, it is pretty shameful Apple has known about this for a year and has not actually fixed it. This seems to be a common occurrence when reporting bugs of any kind. There are plenty of times I have received responses to years-old bug reports claiming a fix was delivered recently, despite the issue still being easily reproducible. And those are little things; this is a bug that, if you believe this EasyOptOuts write-up and Cox’s reporting, fundamentally undermines a privacy feature that costs money.
Old Reddit’s logged-out experience is a significant source of abusive scraping and automated traffic on the platform. It’s also an important interface for many long-time mods and redditors. To strike the right balance between preserving your access to Old Reddit while preventing abusive scraping and automated traffic, over the next month we will start requiring everyone to log in. All logged-in users will continue to have access to Old Reddit, and this change will not impact logged-out browsing on reddit.com.
“New” Reddit is a janky, slow, bloated mess of a website that mostly displays text, images, and videos. “Old” Reddit is ugly but functional. The site admins are not promising the superior version will be available forever, and they are specifically calling attention to its lack of a “modern security tech stack”. I do not think “old” Reddit is long for this world — especially since Reddit is aggressively promoting its mobile app.
‘Steering’ – the ability for developers to engage with customers about off‑platform options – is currently banned by Apple and restricted by Google in the UK. Lifting these constraints would allow developers to bypass mandatory fees set by platforms.
The CMA’s consultation includes principles to ensure that the fees Apple and Google charge for steering are fair and reasonable. Using an evidence-based framework, the CMA would expect steering fees to be lower than current app store charges, with savings passed onto UK customers or invested back into the developers’ businesses to support future innovation.
You will note the CMA is not saying that a smaller fee actually will result in lower prices for customers, because corporations — including developers — tend to be profit-seeking endeavours. They may increase prices when costs grow but that does not mean they do the opposite. But who cares? Lower costs permit more flexibility on pricing and, even if that money ends up in the pockets of developers instead of Apple, is that supposed to be a bad thing? Is there a reason why someone should be upset that they might pay the same amount but an indie developer gets to keep more of it?
The proposed policies are pretty straightforward from what I can see. Among other obligations, Apple is not allowed to use or require scare tactics when users are routed to an external payment mechanism and, while it is allowed to charge a steering fee, it is not allowed to count services not used by developers offering third-payments nor double-count for services already accounted for by other developer fees. Also, the CMA calls bullshit on Apple’s claim that third-party payments are particularly risky (page 32):
We note that Apple already requires the use of alternative in-app payment methods, including steering of users through a link-out, within apps offering physical goods and services. We understand that Apple has distinguished between the approach it takes to digital and physical goods and services for operational reasons, and not because of a different magnitude of risks to user security and privacy.
If this CMA proposal becomes law, it would be yet another country — I believe the seventh region, counting the E.U. as one — in which Apple’s anticompetitive App Store practices have been made illegal.
Between November 2023 and August 2025, Amazon AU’s Prime contracts with more than one million annual subscribers contained what the ACCC alleges were five unfair contract terms that allowed it to unilaterally make negative changes during the contract period without offering subscribers a remedy.
It is also alleged that Amazon AU later relied on one or more of these unfair terms when it introduced ads to Prime Video in Australia in July 2024. Prior to that, Amazon Prime Video was almost entirely ad-free.
Good. Do you know how much people would love it if governments gave adequate time and funding to competition and consumer protection authorities? Going after this bait-and-switch nonsense is something prized by just about everyone more sensible than your average libertarian. More of this, and where I live, please.
Australia’s prime minister vowed on Friday to bullet-proof laws supporting a social media ban for under-16s as the government prepares legal action against platforms amid a steady stream of evidence that the ban has had little impact on teen use.
[…]
He did not give further details about what steps the government would take and the regulator declined to comment.
The details matter. In general, though, anything that makes age gating more effective must presumably make accessing age-gated websites more difficult for everyone. Proponents will argue that it is worth the collective sacrifice because it will add a layer of protection for children. I sympathize with that argument, but I think it over-simplifies a complex story and presents a solution with serious problems — for instance, the possibility of data leaks.
“We have to do something about it as fast as possible, because people will find this and resell it. It will do damage,” Sammy Azdoufal told me in May.
Azdoufal is the security researcher who used Claude Code to help discover that every DJI Romo robot vacuum cleaner and a million baby monitors and security cameras were embarrassingly easy to hack. This time, he says he discovered over 985,000 photo IDs sitting on the public internet for any half-decent hacker to steal.
These I.D.s included passport scans and driver’s licenses because they have the kind of information you need to buy weed. And this is in-person purchasing at clubs in Spain. I am hopeful that age gating technology vendors are more competent, perhaps destroying their copy of a document and storing only a confirmation token. But without better oversight, we simply have no idea and should have no confidence.
(Via Bruce Schneier who, for whatever reason, links not to Hollister’s report but instead a presumably A.I.-assisted rewrite hosted at the domain previously associated with — no joke — Cambridge Analytica.)
As Claude Design catches on among Anthropic users, a generic-design aesthetic is emerging that’s as noticeable as text-based A.I. tics such as overenthusiastic em-dash usage or “not X … but Y” constructions. In slide decks and on website interfaces, there’s a predominance of beige- and cream-colored backgrounds, rusty orange-hued accents, and large serif typefaces that are italicized and highlighted in zealous attempts to emphasize. Subheadings are often “tracked out,” in design parlance, with spaces between the letters, and there’s an inexplicable prevalence of ticker-like text bars, as if the website were a cable-news show. […]
An off-white background? Rusty orange accent colours? Well, darn.
I paused to think about what I found inspiring at this time, and what feels fundamentally me. The answer lay in a mix of blueprints, indigo dyes, and selvedge denim. Add in some mid-century Americana via compartmentalized typography, and here we are. In hindsight, I’ve used shades of blue a number of times with Weightshift, but had left it behind. The blues are back.
I am choosing to see myself as someone who is not competing with A.I. I can’t anyway, on either price or so-called “efficiency.” I probably didn’t want that kind of work anyway. I find myself being more deliberate in design decisions, and writing too, so my work resembles something made, not generated.
Now that a method of mass production has reached the knowledge work sector, it is interesting to see a whole class of people try to find and eradicate any whiff of A.I. from their work, regardless of whether it was put there by human or machine.
Let’s get to one of the big points of the article I started this rant with, that if VR couldn’t be popular during a global lockdown when everyone had lots of free time and was trapped inside, then it would never be popular. While that might be true for Horizon, it is not true about VR in general. Truthfully VR was dying before COVID. I know because I was there.
I worked in Mozilla’s Mixed Reality group from 2017 to 2020. I saw all of this first hand. Most investments were turning sour before COVID.
Marinacci’s closer-to-the-inside voice is worth your time if you are at all interested in this bizarre chapter in tech company history. If anything, I think it lends credence to my theory that the pandemic was the fuel powering these dreams, since it became the justification for maintaining investors’ waning interest — until it was not.
But this isn’t some fluke, or temporary supply chain problem. Companies are choosing data center clients over ordinary buyers because “the same chip earns far more inside an AI server than inside a consumer device,” according to Srikanth Jagabathula, professor of technology, operations, and statistics at the NYU Stern School of Business. Regardless of whether people are clamoring for more AI, and more AI data centers, or not.
O’Brien frames this question around the recent Apple price increases, but this observation can be generalized in a way that does not require tackling the question of whether the company’s extraordinary margins should cushion its customers against increasing costs. If someone wants to go out and buy a computer right now, they are going to be paying through the nose for any spec above the entry-level. Even if they want to buy a relatively “thin” client, it still needs plenty of RAM — in part because local models need it, itself a part of this issue.
There is, therefore, no way to opt out of this technological push when buying something new. That makes sense if you think of the family of artificial intelligence technologies as a feature, not a product. But it does mean we all end up paying for this explosive market regardless of whether we think any of this is a prudent, sensible, or ethical technology.
But while tech giants like Apple and Microsoft, which both announced price hikes this week, have a hefty cash cushion, supply chain leverage and customers numbering in the millions or billions, a much wider swath of businesses face potentially dire straits. Most consumer electronics companies have little margin to spare and can’t confidently raise prices in an economy already grappling with inflationary pressures.
Samsung, SK hynix, and Micron were sued on June 25th in the U.S. District Court for the Northern District of California, where 17 plaintiffs accuse the three memory makers of illegally coordinating to restrict DRAM supply and inflate prices that the complaint says have risen roughly 700% over four years. The class action, filed as Garciaguirre v. Samsung Electronics and assigned to Judge Noel Wise, invokes Section 1 of the Sherman Act and targets companies that together hold around 90% of the global DRAM market. Samsung and SK hynix have pleaded guilty to criminal DRAM price fixing once before, with the latter paying a $185 million fine in April 2005.
The complaint (PDF) and docket are available on CourtListener which, notably, contains a reminder that these same companies did this before.
Perhaps even more notably, when he does wear t-shirts these days, he’s demurely tucking the chain inside: […]
Mark Zuckerberg’s regular reinvention is fascinating to me. There is nothing wrong with his changing how he dresses, just as there is nothing wrong if you or I do the same, but he clearly has a communications goal for these personal makeovers. His discovery three years ago of six-figure wristwatches and ostentatious streetwear was, in part, about signalling allegiance to vulgarity and masculinity when that was seemingly trending. Now, the cultural tides are shifting again and Zuckerberg needs to play the role of a studious and careful CEO who will manage his company’s contributions to artificial intelligence responsibly, so he is wearing soft polos.
Then there are the CEOs who wear the same thing every day, and that is pretty weird, too.
A new pivot point for Apple? Seems like a good time for a new pivot for me, too. This year has been full of milestones for me, from appearing on “Jeopardy!” to reviewing David Pogue’s book about Apple for The Wall Street Journal, to crowdfunding a new podcast about Apple history. Along the way, I’ve had to say goodbye to some longstanding projects.
That’s my long way of saying that this is my last More Color column at Macworld. […]
Snell would likely not appreciate it if I mentioned how old I was when I first read his byline, so I will not, but I will point out that I continue to love what he is doing independently at Six Colors. My congratulations for an amazing run.
Apple’s Certified Refurbished store has been a sanctuary for people who balk at the prices of new Apple products, but it provided little shelter from today’s increases across many of its lines. Reconditioned items are also more expensive.
These increases seem to be driven less by the current refurbished lineup and more by what happens when Apple adds inventory from its newly-pricier products — which sucks. Even explaining it to myself feels dishonest.
“The consumer electronics industry is facing an unprecedented challenge,” Apple said in a statement to CBC News. “We have never seen a component price increase this much, this quickly.”
The company has shielded customers from increases thus far, it said. “But we have now reached a point where we need to begin raising prices on a number of products, including today’s increases for iPad and Mac.”
I do not think you need me to emphasize the qualifier words in that final sentence to understand what Apple is telegraphing. Bummer I did not buy a new Mac yesterday when I could not afford to, so now I can not afford to but even more.
Om Malik passed away on June 24, 2026, at Stanford Hospital after a long health journey with his heart. He was surrounded by family and friends.
I will miss Malik’s writing, of course. I will also miss his photography, where he had found a distinctive and recognizable style that was very often breathtaking.
Here is a little marketing pop quiz for you: the company you work for wants to increase the prices of its products across the board urgently — and by a significant amount — because key components are suddenly more expensive. Which strategy do you choose?
Wait until there is a good time, like the next product launch cycle, and swallow an unpredictable cost increase until then.
Rip the bandage off immediately, knowing this will cause alarming headlines and a corresponding drop in sales that could be expected by making anything more expensive.
Pre-announce it with a small delay, thus giving you a temporary sales boost as people scramble to get their orders in at current prices, and to soften the blow when the increases hit.
The first two options have clear problems. The third has effectively no down-side, given the circumstances, and clearly telegraphs the unusual nature of the increase, which is why it is what Apple went with.
Hartley Charlton, of MacRumors, has the full list of changes in U.S. dollars, to which Apple anchors its worldwide prices:
The average price increase is $269.23. The iPhone, AirPods, Studio Display, and accessories such as the Apple Pencil are seemingly the only unaffected product lines.
In pure numbers, the biggest increase is by $1,300 to the high-end Mac Studio. In relative terms, the Apple TV carries a 50% premium compared to yesterday. In reputation, however, the loser has to be the MacBook Neo, which was launched less than four months ago with its $600 base price a marketing factor as loud as its lime green finish. I do not think it is a worse product at $700, but I think the price bump so close to its introduction indicates the wild world of component costs. Notable, too, that the iPhone lineup remains unchanged — for now.
Canadian pricing is now eye-watering. A few examples:
MacBook Neo: $949, from $799
MacBook Air: $1,799, from $1,499
MacBook Pro: $2,799, from $2,399 (with the M5 Pro, $3,499 compared to $2,999; and with the M5 Max, $5,799 compared to $4,999)
Mac Mini: $1,099, from $799
Mac Studio: $3,499, from $2,699 (with the M3 Ultra, $7,499, from $5,499)
When choosing the URL slug for this post, I first assumed apple-price-increases-2026 would be enough; on second thought, I figured I would add june, just to be safe.
Meta left potentially sensitive information collected from employee laptops accessible to anyone inside the company, according to an internal security notice seen by WIRED and three current employees familiar with the issue.
The data, which was collected as part of a divisive initiative to train artificial intelligence models, is believed to include keystrokes, mouseclicks, and content displayed on the computer screens of Meta’s US employees.
Meta said on Monday it will pause an internal program that tracks employee mouse movements and digital activity for AI training as the social media giant investigates data security concerns.
Meta staying in character by doing something creepy, badly.
Cynthia Khoo, writing for the Institute for Research on Public Policy’s Policy Options:
If Bill C-22 passes as is, it could put in place one piece of a bigger cross-border law enforcement data-sharing system, as envisioned in the CLOUD Act and other international data-sharing treaties.
Once completed, this system could further expose Canadian residents and our human rights to U.S. government and corporate surveillance apparatuses and their well-documented abuses of power. This is the last thing Canada needs in an era of destabilized relations with an increasingly authoritarian Trump administration.
Therefore, the federal government should withdraw Bill C-22’s provisions involving sharing data with foreign states, among other provisions, or otherwise suspend the bill’s progress through Parliament until and unless the government has provided opportunities for full public and parliamentary debate.
Over the last several years it has become readily apparent that there has been a shift in the editorial framing and focus of the New York Times when it regards issues relating to transgender people. This is particularly pronounced when it comes to issues of gender affirming care for transgender youth. The Times has contested this accusation of bias or editorial shifting of their priorities and framing, often by pointing to individual stories and claiming that the stories are rigorously fact checked and true. The issue is that any particular article can be argued about in isolation about whether or not the framing is biased against transgender people but when viewed in the aggregate the shift can become much more pronounced and difficult to defend.
To assess the framing of thousands of articles, Caraballo ran the text through three different large language models plus VADER. Caraballo notes the LLMs fared better at interpreting words in a greater context.
Setting aside the technology, it is alarming to see the Times’ coverage shift, and so noticeably in 2022. Caraballo attributes this to several predominantly internal factors, including losing the paper’s only openly trans writer, but I stumbled across another possible external influence.
[The Manhattan Institute’s] attacks on education also target K-12 schools. Starting in 2022, it began frequentlydemonizing schools for teaching “radical gender” ideology and “transitioning kids without parental consent.” Wuest says this is because disparaging public schools supports its longtime policy goals related to school choice. She cites a 2022 speech by [Christopher] Rufo at Hillsdale College.
The links in the quoted paragraph primarily go to the innocuous-seeming City Journal, though it is a publication of the Manhattan Institute. It ran loads of articles in 2022 from Rufo taking things out of context to, as Pisoni writes, advance the broader conservative policy goals of the Institute and stirring up a broader panic about trans people. And the Timeslovestaking directionfrom Rufo.
The surge in pedestrian deaths has baffled researchers. Most other wealthy countries haven’t seen similar increases, suggesting that possible culprits like smartphones don’t tell the whole story.
Other likely causes of deadly crashes, such as drunken and distracted driving, have attracted immense attention from the public and policymakers. But the trend toward ever-larger vehicles has received much less scrutiny, even after federal researchers in 2022 cautioned regulators that it was endangering pedestrians.
After analyzing federal and industry records, including never-before-examined data on vehicle dimensions, we found that the rise of large pickups and S.U.V.s is an important factor.
I am fascinated by the Times’ repeated investigation into rising pedestrian deaths in the U.S. — here is another story, this one from 2023 — in which reporters notice how it differs from other countries, including Canada, but do not seem to interrogate that question further. The Canadian auto market is extremely similar to that of the U.S. and the sales of large trucks and SUVs has been booming here, too; yet, we have not seen a comparable rise in pedestrian injuries or fatalities. This is something I explored in response to that 2023 article because it is personally relevant: I am most frequently a pedestrian and cyclist, and I would prefer to not be hit by a vehicle.
Since I published that, researchers from the Insurance Institute for Highway Safety published an extensive comparison (PDF) of this divergent trend in general traffic fatalities. Though not specific to pedestrian deaths, they point to a variety of different factors, including greater adherence to speed limits in Canada, lower speed limits on average, greater transit use, stricter enforcement of impaired driving laws, and climate-related factors. But this data is only up to 2021 for the U.S. and 2020 for Canada — and those years had specific and unique differences.
Those researchers, in turn, cited a 2022 Bloomberg article by David Zipper, specifically comparing collision fatalities in the U.S. and Canada. I wish I had read that article first; it is very good. Zipper points to factors like growing average vehicle use in the U.S. compared to a flat trendline in Canada, no doubt influenced in part by much lower U.S. fuel prices. And, yes, Zipper also pointed to a trend toward larger and heavier vehicle purchases in the U.S., even more than in Canada. All of these things add up. If people are driving bigger and heavier cars over an already-higher speed limit for greater distances while being more likely to be impaired or distracted, that is likely to cause a much higher number of fatalities than can be explained by any one of these factors alone.
In his article, Zipper quoted Ian Jack, of the Canadian Automobile Association, saying “[it] worries me about the future here in Canada, because we often end up emulating the U.S. some years later”. This, unfortunately, appears to be true. Transport Canada’s motor vehicle casualties dashboard shows a modest increase in pedestrian deaths in 2023 compared to 2022, and a massive increase in all deaths in 2022 and 2023. Injuries are also on the rise, though the story there is more mixed: total injuries are climbing from a low point in 2020, though not to the pre-pandemic levels, but pedestrian injuries spiked in 2020 compared to preceding and subsequent years.
In Alberta, specifically, we seem disinterested in learning anything. Speed camera use has been sharply curtailed and the province has raised the speed limit of a busy stretch of highway. The result is a modest increase in collisions overall in the province and a significant increase in fatal and injurious collisions, including a record-breaking number of fatalities last year in Calgary. Some of that is, undoubtably, due to the factors in this Times article about big trucks and SUVs which, unfortunately, are still growing. Chevrolet just announced its newest Silverado pickup truck line “with a bolder stance [and] stronger face”, one trim level of which, according to Motor Trend, “include[s] a 2.0-inch lift that makes it one inch taller than 2026”.
Meta has a booming business, and is already a beneficiary of AI via increased ads revenue. Meanwhile, my Facebook feed is filled with fake, AI-generated videos, with hundreds of comments from bots and people who seemingly don’t realize it’s AI. It all seems like just more content for Meta to show ads next to.
And yet, despite business booming, Meta’s leadership has gone on a crusade to inflict the most damage possible on its engineering org. Apparently, they’re now learning that most of it was pointless.
Just a devastating assessment of Meta’s cultural shift from an organization that values software engineers to one that is very excited to see them minimized. This is already impacting users — see above, the month of account hijackings, and so on — and its software engineers. But Meta is not accountable to them as much as it is to advertisers and, so long as it continues matching ads to users, the money will keep flowing.
Apple announced this week it would be implementing its “alternative app marketplaces” and “alternative app payments” schemes to residents of Brazil after a settlement with the country’s antitrust authority. Michael Tsai has a good roundup of the history of this settlement and reactions from developers.
The people living in places where Apple’s standard App Store policies have been found non-compliant has now reached one-third of the world’s population. That is a poor measurement, of course, and half that is thanks to the mildly adjusted commission in China. But it has all happened recently, and it goes to show the number of influential markets taking this seriously. Even in the U.S., developers are allowed to link to an external purchasing option, effectively its sole concession of the lawsuit filed by Epic Games. Which raises the question: what are Canadian regulators waiting for? Apple is clearly not going to correct its policies without governments stepping in.
I think these policies are similar to those implemented in Japan — Apple even recycled the press release, swapping only the local details. But because these policies are all being revised piecemeal and region-by-region, and because Apple has a whole bunch of separate fees and commissions related to third-party distribution, I am trying to put together a comparison to better understand how this plays out in the real world.
Apple plans to raise prices on its products to offset the surging costs of memory and storage chips, Chief Executive Tim Cook said in an exclusive interview with The Wall Street Journal.
“Unfortunately, price increases are unavoidable,” he said. “We’re doing our best to mitigate the huge increases that are being passed to us, and we’ve been trying to shield our customers from the increases, but the situation has become unsustainable.”
During its holiday quarter, Apple’s profit margin on hardware was 40.7%; in its most recent quarter, that dropped to 38.7% — a remarkable figure for physical products. It is these high margins that led to analysts like Ming-Chi Kuo to claim Apple would keep prices more-or-less stable and offset the additional costs through its even higher-margin — 76.7% — services business. The launch of the MacBook Neo and iPhone 17E a few months agoconvinced some that Apple would hold steady.
That Cook is pre-announcing these increases suggests to me this will not be a modest bump coming with the release of new products later this year. It indicates the current lineup will cost more, and products launching later could cost a lot more — partly because well-funded A.I. companies are pre-purchasing production capacity, and partly because Apple Intelligence features have a new RAM floor. All I know is this — plus the gangbuster sales of Mac desktop models — really throws a wrench in my personal purchasing plans.
If I take a screenshot of your app at any moment, you should be able to explain what I see.
Why care about every frame? It builds trust. Users can’t see the code, so UI is the only way for them to judge the quality of the app. If UI looks good, that means developers had time to polish it, which means that they probably spent a comparable amount of time to iron out the code. It’s a heuristic, but a reasonable one.
Prokopov lists several criteria, but this post is almost wholly dedicate to the last one: “precise animations”. More specifically, in the case of this article, a lack thereof, particularly throughout MacOS and its first-party apps. I loved this post, and Prokopov did not even mention one of the most glaring in MacOS Tahoe: the four-finger trackpad gesture, the one that used to show Launchpad, now displays the App Drawer before the animation plays, then plays the animation, then shows the App Drawer again. If animations like these ship, it certainly raises questions about what else was deemed unworthy of being fixed.
Later this summer, Apple will unify the email domains used by Sign in with Apple and iCloud+ Hide My Email under a single, shared domain: private.icloud.com.
New addresses generated for both features will be issued on the new domain. […]
Previously, Hide My Email addresses were generated on icloud.com, the same domain as any other iCloud email address. This made it basically impossible for web admins to block registration using Hide My Email. After this change, they can just block signups that use private.icloud.com. Some similar third-party services have a list of alternative domains for creating an email account, and I hope it is possible to use icloud.com in addition to the unified subdomain — but if it were, Apple probably would have said that.
Credit Where Credit Is Due
I have previously noted I am not a fan of Ed Zitron’s writing on A.I., which I think is driven more often by adherence to narrative than by genuine skepticism. Even so, his newsletter is extremely popular, and occasionally that pays off with honest-to-goodness scoops. Yesterday, he got a big one — a smattering of OpenAI financial documents revealing the company’s spending and earnings for the past two years. In 2024, it made billions of dollars less than it spent — including over a billion dollars on sales and marketing alone — and its 2025 numbers look even worse:
The financial condition of OpenAI is deeply concerning. $38.53 billion in losses are astronomical, and far higher than most believed it would be. Losses also appear to be mounting year-over-year at a dramatic rate, and I’m not sure how this company finds a way toward any kind of sustainability or profitability.
Zitron shared these documents with the Financial Times, which independently verified them, and added some much-needed context. In particular, that whopping $38.5 billion loss accrued in 2025 and highlighted by Zitron — including in his headline — seems far less dramatic:
Before OpenAI’s switch late last year to become a public benefit corporation, investors in the company received convertible interest rights rather than conventional equity. Under US accounting rules, those interests were treated as liabilities and periodically revalued as the company’s valuation increased.
As OpenAI’s worth rose, the increased value of those investor rights created a roughly $30bn charge, added the person. The charge is not expected to recur following the restructuring, they said.
That expense is not something that can be waved away, of course, but it does not seem to be materially related to the company’s actual costs of creating and selling its products. Losses without including that charge were, according to the Times’ “person familiar with the matter”, $8 billion, or roughly 60% more than in 2024. But that is against revenue of $13 billion in 2025, a significant increase over 2024’s $3.7 billion. (OpenAI, in the first three months of 2026, earned $5.7 billion.)
These juicy numbers were republished by outlets like Reuters, the Next Web, Stocktwits, Benzinga, and Startup Fortune. Shamefully, all attributed them solely to the Times without mentioning Zitron’s critical role. These publications — particularly Reuters — should be giving full credit to the original source.
That Zitron now has actual, verified numbers also allows us to check some of his own reporting. For example, in April, he was quite upset that “every outlet has continued to repeat that OpenAI ‘made $13 billion in 2025,’ despite that being very unlikely given that it would have required it to have made $8 billion in a single quarter”. It is unclear to me which outlets Zitron is referring to as I could find just one — Russia Today — using that quoted phrase verbatim.
Even so, Zitron goes on to write about some apparently conflicting numbers reported by Anthropic before concluding:
Though I cannot say for certain, both of these situations suggest that Anthropic and OpenAI are misleading their investors, the media and the general public. If I were a reporter who had written about Anthropic or OpenAI’s revenues previously, I would be concerned that I had published something that wasn’t true, and even if I was certain that I was correct, I would have to consider the existence of information that ran counter to my own. I would be concerned that Anthropic or OpenAI had lied to me, or that they were lying to someone else, and work diligently to try and find out what happened. I would, at the very least, publish that there was conflicting information.
Two days after this article, he again claimed that “every single story about OpenAI’s revenue other than my own reporting (which came directly from Azure) massively overinflates its sales”, which are more like “a mere $2.27 billion in the first half of last year”.
The numbers Zitron now has for OpenAI suggests this narrative is complete hogwash. Yes, these companies leak overly-optimistic annualized run rates, but if that was a factor in the audited financials Zitron obtained, he likely would have mentioned that. He does not — and neither does the Times, for that matter. “Due to the seriousness of this story”, Zitron wrote, “I am not going to do very much editorializing”, so we will see in a later issue of this newsletter whether he acknowledges this self-induced frenzy was all in his head.
This is why I read Zitron’s work in the framework of conspiracy thinking. He accused OpenAI of “massively overinflat[ing] its sales” and “misleading their investors” based on his own calculations using leaked Azure figures. But it turns out OpenAI did, apparently, have that $13 billion in real non-ARR-fudged revenue for last year, and its operating loss is shrinking. Real analysts, not me, can figure out whether this company is on a path to a functional business. Zitron conjured a whole fictional narrative out of misreading some numbers and then, it would seem with this latest update, misunderstanding them again because it is useful for the story. Still, he should be credited for this scoop.
What’s striking about the Intel Mac era is that Apple switched to and away from Intel chips for basically the same reason: It was looking for a more compelling processor roadmap and the best possible performance-per-Watt for its chips. When Intel was executing well—and during the decade between the mid-00s and mid-2010s, Intel was executing exceptionally well—Apple wanted in. It was only after years of watching Intel struggle that Apple wanted out.
Apple used Motorola CPUs for ten years, PowerPC processors for eleven, and Intel for fifteen. Unbelievably, we are already six years into the Apple Silicon Mac era.
Given the kinds of things made possible by the ARM-based processors in today’s Macs, it is difficult not to imagine this transition was inevitable, though perhaps catalyzed by the Intel models in the mid-to-late-2010s. I harbour a small fascination with the culmination of issues in that generation of Macs not limited to the processors; Cunningham points to a former Intel engineer’s comments that Skylake generation processors were a key point of friction. If you know a lot about the engineering story behind those Macs, like the keyboards, I would love to hear from you, perhaps on Signal.
Customizable select is coming to Safari 27. With this technology, developers can fully control the appearance of <select> elements — custom arrows, option layouts, color swatches, icons, full visual styling — without the need for JavaScript libraries or an endless parade of <div> elements. And because it’s a built-in control, you don’t have to compromise on keyboard navigation or accessibility semantics.
If you have ever tried to build a really nice-looking site-specific <select> menu, this is probably a huge relief. It certainly is to the me of a past life, back when I did a lot more front-end development day-to-day. Support for the base-select value began rolling out to other browsers last year.
The media focused on the higher age limit — it’s been happening in other parts of the world and is easier for people not well-versed in tech policy to understand, including many journalists — but it was not really the centerpiece of the legislation. If anything, the age limit serves as a stick to get companies to comply with a broader set of design standards meant to make their platforms safer for younger users. Unlike in the Australian legislation, if platforms make those changes, they can win an exemption from the age limit.
I also appreciated the implied nuance in the legislation; however, critically, those design standards have yet to be defined. Perhaps users will be granted actual control over what they see in their feeds; perhaps there will be legally defined promises for what notifications users may opt into or out of. These would be welcome improvements. But we simply do not know what they are yet.
Worse, by tying all-user policies on the one hand to an age gate on the other, I worry the outcome will be a compromise satisfying neither. Someone is currently supposed to be 13 or older to have an account with a social media service, both under Canadian law and in platforms’ terms of service agreements. Raising the floor to 16 is not the biggest issue one way or another. The real carrot is, therefore, weighing whether social media companies are willing to stop mandating their slot machine for feelings on every Canadian user in exchange for not having to verify their ages. Given the number of places already enforcing some age-gating and the development of infrastructure associated with that, I think many social media platforms will find it far easier to start carding people rather than changing their ways.
I do not think an imperfect law is inherently bad, however. Like Marx, I am encouraged to see a worldwide discussion among policymakers of how to rein in these specific kinds of businesses that have marketed directly to children despite their many design flaws for which these companies accept no responsibility. I am only skeptical these companies will do the right thing when they always prefer the cheaper and less accountable option.
Bill C-34, the Safe Social Media Act, would force social media services — defined as traditional social media platforms, live-streaming services and adult content services focused on user-shared content — to restrict accounts for children under 16 years old.
However, services could seek an exemption if they implement what officials briefing reporters called adequate safeguards to protect children. The exemption wouldn’t apply to platforms offering adult content services.
The “adequate safeguards” are not yet defined and, it turns out, are far from the only things to be determined. It was striking to read the text of the bill and come across so many key pieces punted to a later date or committee. Some of these policies, for example, might only apply to services over some number of users, but that cut-off is to be established later. There is a whole committee, the Digital Safety Commission, with “three to five full-time members” but few specific details. Even things which appear to be strictly defined — removing CSAM within twenty-four hours of being flagged by a user — might be different “if a period of a different length is provided for by regulations”.
Bill C-34 suggests the government absorbed only part of the lesson. The Criminal Code and Human Rights Act provisions are gone, but in their place the government has thrown in everything else: the original Online Harms Act platform duties, an under-16 social media ban backed by mandated age verification, Bill S-209’s pornography age verification requirements, a new AI chatbot regulatory regime, and sweeping powers for a Digital Safety Commission that will write the rules, enforce them, and decide which platforms escape the ban restriction. It is an everything-all-at-once approach in which nearly every key component, including which services face the restriction, how age gets verified, which AI systems are covered, and what standards govern exemptions, is left to regulations that do not yet exist.
The internet has plenty of problems that deserve attention. Predators exist. Addiction is real. Platforms optimize for engagement over well-being. None of those facts requires the rest of us to accept a system of digital ID that will follow every user who wants to comment on the news or express their position on whatever.
There is the tiniest, faintest shred of hope in that some platforms implementing “adequate safeguards” will not actually need to verify ages at all. I am not banking on that, to be clear, but it is at least a notion of something that could be promising. Then again, we have no idea about what that means or, in fact, any material policies in this bill. All we have is this framework, and it sucks.
Do you want to block all YouTube ads in Safari on your iPhone, iPad, and Mac?
Then download Magic Lasso Adblock – the ad blocker designed for you.
As an efficient, high performance and native Safari ad blocker, Magic Lasso blocks all intrusive ads, trackers, and annoyances – delivering a faster, cleaner, and more secure web browsing experience.
Magic Lasso Adblock is easy to setup, doubles the speed at which Safari loads, and also blocks all YouTube ads — including all:
video ads
pop up banner ads
search ads
plus many more
With over 5,000 five star reviews, it’s simply the best ad blocker for your iPhone, iPad, and Mac.
And unlike some other ad blockers, Magic Lasso Adblock respects your privacy, doesn’t accept payment from advertisers, and is 100% supported by its community of users.
An investigation by the Privacy Commissioner of Canada has found that Grok’s AI image-generation tool was launched without proper safeguards or sufficient consideration of potential privacy harms.
This lack of protections allowed users around the globe to create and share non-consensual, sexualized deepfakes, many targeting women and children.
In a report released today, Commissioner Philippe Dufresne found that X Corp. and xAI violated Canada’s federal private-sector privacy law.
According to the full report, while a privacy impact assessment was completed of the previous version of Grok’s image generation model, one was not done for Grok Imagine until March, well after its July 2025 launch. Even then, the assessment “did not accurately reflect […] risks to security, safety and privacy”.
Tech mogul Elon Musk encouraged “repeated and loud” protests ahead of Northern Ireland’s immigration demonstrations, some of which flared into violence.
The owner of X, formerly Twitter, went on to comment that “only Restore Britain can save Britain” over the course of comments on a horrific knife attack carried out by a Sudanese man on the streets of north Belfast.
For context, Restore Britain is the political party for people who view Nigel Farage as a soft and cuddly liberal.
Asked Wednesday why the world’s richest man spends his days in a bitter online culture war instead of enjoying his billions on a beach, Musk posted: “Nothing else matters if civilization falls.”
Musk’s definition of “civilization” is white people. He loves to cast himself as a saviour of humanity, but juggling multiple CEO positions apparently leaves him with enough time in the world to tweet with abandon. Musk has zero relationship with the people he is inciting to cause harm, yet his behaviour and his companies’ track records have no bearing on his finances or his influence. He will become the world’s first trillionaire tomorrow morning. He is just a guy, though, with a cushy white-collar job and an internet connection. It is upsetting to be reminded that much of our world is run by shameless psychopaths.
Siri Takes on Siri, Now Old Enough to Drive
In March 2018, I compared the original 2010 demo of Siri against the then-current shipping version. That was eight years ago — closer, in fact, to the launch of the iPhone 4S and Apple’s version of Siri than to today.
Not much changed after I did that little experiment until Monday, when Apple announced a “profoundly more capable” Siri. Called Siri A.I., it will officially launch in beta with this year’s operating system upgrades. But I recently got access to the first preview of it in the first developer build of iOS 27 and, naturally, I had to try the same set of queries.
“I’d like a romantic place for Italian food near my office”: Apple’s previous Siri implementation always — for me, at least — got tripped up by the “near my office” part. New Siri did this flawlessly.
“I’d like a table for two at Il Fornaio in San Jose tomorrow night at 7:30”: Outside attempting this demo in 2018 and again today, I have never tried to book a restaurant reservation using Siri, so my sample size is pretty small. Last time I did this, I once managed to get Siri to prompt me to make a reservation through OpenTable, but was otherwise greeted by an error.
New Siri did one of two things: on some attempts, it told me it could not book a table for me, but suggested I could add it to my calendar or call the restaurant to complete the reservation. On others, it added the event to my calendar and asked if I wanted Siri to call the restaurant to complete the reservation. It is interesting to me that Siri A.I. does not (yet?) throw to OpenTable, and only suggests I make an old-fashioned phone call.
“Where can I see Avatar in 3D IMAX?” I swapped “Avatar” for a current 3D IMAX movie, and Siri A.I. showed me one theatre locally that is showing it in 3D but not IMAX, and one that is only showing it in 2D IMAX. This is, I think, mostly fine. I think Siri should clarify that no theatre nearby is showing it in 3D IMAX, but I think this is preferable to showing me the nearest theatre matching the query literally. As with the restaurant example above, there is no way for me to buy tickets through Siri.
“What’s happening this weekend around here?”: In the original Siri demo, this only showed nearby public events for the weekend. Apple’s version, in 2018, thought I was asking about the news and then, after rephrasing twice, threw to a web search.
Siri A.I. interprets this differently than either. It showed me my calendar and the events I already have this weekend, and then found an event in a marketing email in my inbox “if you’re looking for something else to do”. There were no details presented beyond “a ticketed show” and no obvious followup, but after a followup question — “what is that event?” — it showed me more information and a button to open the message.
In the original Siri demo, they ask a followup question “how about San Francisco?”, so I did the same, and it showed me events happening there this weekend. Just what you would expect.
“Take me drunk I’m home”: Siri got me driving directions to my house.
Though this is a test conducted on the very first version of Siri A.I. from a fixed point in Calgary, it seems to work quite well. So far, it is better than any version of Siri Apple has released yet and, as you can see above, it is almost as good as the original 2010 demo, before Apple acquired the company.
Apple today introduced Siri AI, an entirely new version of Siri, powered by Apple Intelligence. Unfortunately, due to the Digital Markets Act (DMA), Apple will not be able to ship Siri AI in the European Union with the release of iOS 27 and iPadOS 27. Over the past several months, EU regulators did not accept any of Apple’s proposed solutions to bring Siri AI to the EU while safely supporting other virtual assistants.
Thomas Regnier, a European Commission spokesperson, responded during a press conference:
We had a few contacts with Apple on this matter, this I can confirm. But Apple was simply unable to develop interoperability solutions that meet essential E.U. privacy and security standards.
Instead of trying to find a suitable compliance solution, Apple simply made a request to the European Commission to be exempted from their interoperability obligations under the DMA — and this for at least 18 months on top of it.
Guess what? That’s not an option. Because it would mean that no A.I. agent other than Siri A.I. — by the way, powered by Google — would have an equal chance to be chosen by iPhone users.
It is refreshing to see Apple and the European Commission arguing in public and on the record instead of by leaking information to the Financial Times.
Nicolas Lellouche, of Numerama, spoke with Greg Joswiak about this (machine translated; original in French):
To work, Siri AI builds a semantic index of all your communications and data so that you can find them when you ask them a question. Apple suggests that advertisers will use AI to retrieve this data if Europe forces it to open its accesses: its system is totally incompatible with European requests. A third party could “read all your messages, edit your files, delete things, delete your photos, take actions in your applications without you knowing or consenting,” lists Greg Joswiak.
Apple and the European Commission each cite privacy and security concerns as justification for their competing arguments. This is a little study in clashing definitions, but it rings a little hollow. To the extent Apple has concerns about third-party A.I. access, it will still launch Siri A.I. on MacOS, which remains a relatively unrestricted system where, I hear, dozens of third-party apps may already exist. A.I. assistants operating in this environment certainly have security and privacy risks, and the Commission maintains it should be a user’s choice about whether to assume those risks while government should regulate specific and egregious problems.
In its press release, Apple says its proposal for iOS and iPadOS involved the introduction of a “Trusted System Agent — an intermediary that would allow virtual assistants to safely access the same features and capabilities as Siri A.I. for devices in the E.U.”, which Apple says it would have been able to release in the next year-and-a-half. This is the “exemption” Regnier is referring to. According to Lellouche, Apple claims “none of its engineers are currently working on solutions to open Siri AI to the competition”, so perhaps the Trusted System Agent proposal goes nowhere, or maybe it will re-emerge in late 2027. Given Apple’s self-imposed problems with Apple Intelligence since WWDC 2024, I question whether many people in Europe will find this particularly disruptive or upsetting, however.
Fresh off the WWDC keynote presentation, The Verge has been invited to an “on-the-record technical deep dive into the bold new architecture enabling Apple Intelligence capabilities.” Apple SVP of Software Engineering Craig Federighi and his team will be there, and so will we.
No video, but it looks like there was a presentation and a few live demos totalling about forty minutes, then about nine minutes responding — sort of — to pre-submitted press questions. Apple has not returned to live presentations, but this press Q&A and the carefully shot presentation demos are clearly a deliberate way of avoiding questions about whether any of this stuff is real. Once bitten.
You might think, based on the volume of her Facebook posts, that Nieta Aqila is an Albertan who supports separation.
“I signed the Alberta independence petition” because “Canada is not a great country anymore,” an account in her name wrote in a popular Facebook group called Alberta Independence that promotes the movement and has more than 100,000 members.
[…]
But the account owner, according to a CBC visual investigation, was posing as a Canadian and is actually a noodle merchant and content creator from Indonesia, who in some cases was just stealing content from real Albertans.
You might remember the Dutch YouTube channels running a similar playbook: find controversial and newsmaking topics, generate material, and rake in a cut of the ad revenue. In purely financial terms, it is not a bad gig, particularly for this person who lives in a region where minimum wage is about USD $220 per month. An extra USD $14 per month from Facebook, which is what they reported earning in April, can be meaningful. (A screenshot in this article shows a much lower take in previous months.)
The flattening of media into “content” is partly to blame for why this stuff can happen. It appears to get little attention as-is, but it would get none at all without the samey generic framing created by Facebook and YouTube. It is also unlikely a random person in Indonesia or the Netherlands would want to make these kinds of posts without the monetization programs provided by these platforms.
Today’s live stream was a little over an hour long — the shortest presentation since 2005 — but, if this big list of refinements captured by Jonathan Reed, of MacStories, is representative of what will be shipping in September, I am not disappointed. Some choice bullet points, in no particular order:
Uniform toolbars
[iOS] Lock Screen consistently stays awake while scrolling notifications
More distinct active windows [in MacOS]
Search for photos and videos using additional metadata
These are a few things I have previously complained about or filed feedbacks against. Plus, there are a whole lot of things that begin with the words “faster” or “more reliable”. I would like to see this every year, of course, but this appears to be a long-overdue correction.
One more thing I would like to highlight:
New keyboards for Indigenous languages including Blackfoot, Comanche, Cree, Kiowa, and Tsuu’tina
For about ten years, third-party keyboards from an app called FirstVoices have provided support for these and other Indigenous languages, and it is encouraging to see first-party attention, too, for languages at risk of extinction. While there are around 2,500 people living in Tsuut’ina Nation, located adjacent to Calgary, the Tsuut’ina language is spoken by only about 150 people as of 2021 thanks to a history of concerted efforts by colonial powers to stamp it out.
Update: It is disappointing that MacOS 26 is the last version supported on Intel Macs, meaning there are a bunch of people who updated to the slow and janky version of MacOS who will not receive any of the speed, stability, or performance improvements coming in MacOS 27. This is a little like a Mac OS X Snow Leopard year all over again. That version dropped support for PowerPC Macs and was only available for Intel models. Perhaps dropping legacy support is one reason for these refinements.
According to the data breach notice filed with Maine’s attorney general’s office late on Friday, Meta notified at least 20,225 people that their accounts had been compromised, including 30 people in Maine.
[…]
According to Maine’s listing, the hacks began around April 17 and lasted until this week, when Meta said that it had secured the chatbot. Instagram reportedly started notifying affected individuals earlier this week by sending a password reset notification, even as some reported that the hacks were ongoing.
It got worse again. That is a large number of accounts but, more notable to me, a long duration for this vulnerability to be live, from less than a month after the A.I. support bot launched until last week.
One day after WIRED revealed that Meta had quietly embedded an unreleased face-recognition system into an app installed on more than 50 million phones, the company removed it, according to a WIRED analysis of the latest version’s code.
Once again, the pugilistic but ultimately cowardly Meta communications team had no comment of substance for what is, despite their public protest, a worrisome feature that is clearly moving through development.
Do you want an all-in-one solution to block ads, trackers, and annoyances across all your Apple devices?
Then download Magic Lasso Adblock — the ad blocker designed for you.
With Magic Lasso Adblock you can effortlessly block ads on your iPhone, iPad, Mac, and Apple TV.
Magic Lasso is a single, native app that includes everything you need:
Safari Ad Blocking — Browse 2.0× faster in Safari by blocking all ads, with no annoying distractions or pop ups
YouTube Ad Blocking — Block all YouTube ads in Safari, including all video ads, banner ads, search ads, plus many more
App Ad Blocking — Block ads and trackers across the news, social media, and game apps on your device, including other browsers such as Chrome and Firefox
Apple TV Ad Blocking — Watch your favourite TV shows with less interruptions and protect your privacy from in-app ad tracking with Magic Lasso on your Apple TV
Best of all, with Magic Lasso Adblock, all ad blocking is done directly on your device, using a fast, efficient Swift-based architecture that follows our strict zero data collection policy.
With over 5,000 five star reviews, it’s simply the best ad blocker for your iPhone, iPad, Mac, and Apple TV.
And unlike some other ad blockers, Magic Lasso Adblock respects your privacy, doesn’t accept payment from advertisers, and is 100% supported by its community of users.
So, ensure your browsing history, app usage, and viewing habits stay private with Magic Lasso Adblock.
But on Friday morning, a random productivity app called Cириус broke into the top three.
[…]
The reality seems to be that the app is a Russian banking app disguised as a Pomodoro timer. Activity on Telegram this week points to the app actually being a client for Russian financial institution VTB Bank.
The link on “VTB Bank” goes to Wikipedia instead of VTB’s website, where the first tab on the home page slider is currently advertising this app. (Update: It has since been removed.) It is barely disguised. In Russian media, the developer says there are other apps lined up to take the place of this one after it is inevitably removed. Apple and Google have repeatedly failed to catch apps violating U.S. sanctions.
Hall:
The app will almost certainly be pulled soon, but it’s always surprising that existing systems in place sometimes miss detecting apps disguised like this.
Again and again, the world’s leading social media companies have targeted students, even as complaints have mounted that they are hurting teenagers’ mental health and academic performance, according to a New York Times review of internal documents that lay bare for the first time these tactics to hook young users.
[…]
The companies’ push to keep children glued to their screens has overshadowed concerns from parents, teachers and even their own trust and safety teams about interfering with school, according to the documents and interviews with dozens of parents, teachers and former tech company employees.
I do not think it will be surprising to many readers that these companies had strategies to increase usage by children, even during school hours, but I do think it is notable to see it spelled out in these documents. The popularity of these apps is not organic or foretold; it is, at least to some extent, created. There is no reason why Meta would need Instagram “ambassadors” at schools (PDF) to “drive product adoption” if it were not trying to increase Instagram use among teenagers.
Valentino-DeVries:
Members of the company’s [Google’s] education department were often excited about products they thought could improve learning, such as affordable laptops and educational YouTube videos, according to court documents and interviews. They worked alongside product managers, however, who were focused on a different upside: increasing YouTube’s viewership.
YouTube is maybe the trickiest of all these platforms to govern within schools because it has no alternative. There is a vast library of genuinely educational and informative video on the site, and then there is the rest of YouTube. It therefore makes sense to allow its use among students and within schools. However, YouTube has also been honed for boosting engagement, something which affects all users. That is not to say we should have exactly the same standards for children and adults, but it highlights the difficulty of using a singular platform with general-market financial incentives in an educational setting.
Meta has quietly embedded face-recognition technology for its smart glasses into an app downloaded to millions of phones, according to a WIRED analysis of the company’s software.
[…]
Three AI models powering NameTag have already been deployed from Meta’s servers and now reside on its customers’ phones, according to WIRED’s analysis, which was independently reproduced by outside experts. One model detects faces, one crops them, and a third encodes them into biometric data.
Facial recognition, as Mehrotra and Cameron repeatedly note, is not yet enabled. But according to an Electronic Frontier Foundation researcher who tried the existing code, it appears to be partly functional.
Meta communications troll Andy Stone is really mad about this story and, on X, even claimed the “feature doesn’t exist” (Xcancel). Last time I spilled water across my keyboard, I was just happy my laptop still worked properly, but it seems that in Meta’s case, it resulted in writing an entire facial recognition feature and pushed it to production. Incredible stuff.
The New York Times reported on Meta’s rollout strategy for the feature earlier this year (previously linked), while Ryan Mac, then at Buzzfeed News, wrote in 2021 that Andrew Bosworth said facial recognition in smart glasses was something the company was exploring. On X, Bosworth built upon Stone’s reply (Xcancel) to this article claiming it is “incredibly misleading” and “dishonest”, for no particular reason.
Some companies are irredeemably bad and rotten to the core. The sooner Meta runs out of money and closes up shop, the better the world will be.
If you are still using Microsoft Office 2019 for Mac, it will stop working fully on 13 July 2026. Word, Excel, PowerPoint, and Outlook will enter “reduced functionality mode” — a euphemism meaning you can view and print documents but cannot edit, save, or create new ones. Microsoft’s documentation doesn’t clarify what this means for Outlook users.
Why is this happening? A certificate expiration is forcing Office 2019 into read-only mode, though Microsoft acknowledges this only obliquely in the FAQ. Without a current certificate, the apps can’t confirm you have a legitimate license.
Engst compares Microsoft’s approach to Apple’s when it issued an update earlier this year for decade-old iPhones, with a new certificate that allows iMessage and FaceTime to keep functioning. While Apple’s approach is welcome, it is also a good reminder why this proprietary service should always be paired with support for open standards like SMS and RCS.
[…] The customer did their part by paying; it was the company that chose to impose the activation model in order to weed out cheaters; shouldn’t it then own any problems that creates?
But it’s actually worse than that because even subscribing to Office 365 doesn’t fix the problem. You need a newer version of Office, which necessitates a newer version of macOS, which may necessitate getting a new Mac — all to fix what seems like an artificial problem.
My workday began with a notification from Teams that the desktop app will stop working on 20 July, as Microsoft says it is only compatible with the three most recent versions of MacOS. The oldest supported version, therefore, is MacOS Sonoma and, given Apple’s own support policy, that means only Macs released in the past eight years or so are supported. Even though many Macs from that era remain capable and fast, eight years is a long time, and Teams remains available through a web browser.
Also today, OneDrive automatically updated to a newer version, which is incompatible with the version of MacOS I am running. I received no warning until I tried launching it. Microsoft provides no support for this kind of problem for end users but, luckily, I had a Time Machine backup I could use. However, I realized OneDrive would probably automatically update and I would have to do all this all over again, and it contains no relevant preferences. So I needed to delete the related files in /Library/LaunchAgents and /Library/LaunchDaemons and then, thanks to a tip from Sébastien Marchal, block the updater domain in my /etc/hosts file.
The software Microsoft makes is often the kind of thing people are required to use for their job. We do not have a choice of whether to have it installed. It would be nice if Microsoft cared just a little bit more about the durability of what it ships.
The bad blood between the super PACs comes as powerful Silicon Valley companies race to shape the future of A.I. regulation. The groups are two of the biggest spenders in this year’s midterm elections, laying out nearly $24 million and promising that over $100 million more is on the way.
Their financial duel is effectively a proxy war between two of the biggest A.I. companies, Anthropic and OpenAI. One super PAC, Public First, is allied with Anthropic, while the other, Leading the Future, is aligned with OpenAI.
If those names sound familiar to you, it could be because I covered this topic last month. Schleifer’s story is, of course, far more in-depth and better-sourced — and, as an outsider, it is a story that does not leave me feeling particularly confident in the A.I. policy prospects in the world’s most powerful country.
The amount of money A.I. companies have on hand is truly staggering. Of course all of them are spending tens of millions of dollars to influence the results of a midterm election, just like how Formula 1 teams, which used to be plastered in cryptocurrency ads, are now covered in logos for A.I. companies. It is only going to get worse.
OpenAI posted a response to its website claiming it has “not made donations to any super PACs”. This appears to be technically true, though not meaningfully so, as Leading the Future is funded by OpenAI co-founder Greg Brockman and its founding was encouraged by OpenAI’s chief global affairs officer. OpenAI says “any engagement with that organization has been in a personal capacity, not on behalf of the company”, but the distinction between personal and business involvement seems wafer-thin when it comes to executives and super PACs reflecting the interests of the company they run.
The widespread hacking campaign that relied on simply asking Meta AI’s chatbot to take over a victim’s Instagram account appears to have continued even after the company said the issue had been resolved. Meanwhile, the company has been scrambling to secure the targeted accounts and alert victims.
It is not very often for there to be an update on a security incident where it is less severe than originally reported, and I cannot remember a time when Meta has ever been able to provide such welcome news. And it is not as though this is some obscure or difficult-to-use way to hijack an account. If Meta has communicated to users any steps they can take to reduce the likelihood of becoming a victim, I have not received it.
His [Bill Gates’] carefully crafted image has been shattered as more details of Gates’s association with the late Jeffrey Epstein have spilled into public view, challenging prior efforts by the 70-year-old to downplay his relationship with the sex offender. In a February town hall with foundation employees, Gates owned up to two affairs with Russian women referenced in Epstein’s emails.
[…]
Two different polling teams — at the Gates Foundation, and his private office, Gates Ventures — for years have closely tracked opinions about Gates, including on favorability, trustworthiness and inspiration. A media analysis prepared for the Gates Foundation found that there had been a more than 40% increase in “critical news narratives” about Gates and the foundation since the Epstein files were released through February, according to internal documents reviewed by The Wall Street Journal.
There are so many little details in this story that are worth your time, but my big takeaway — aside from the Epstein stuff — is the neurotic obsession with building image that, I imagine, is fairly common among public figures. I know this, of course; you probably do, too. But to see it spelled out in the way Glazer does is quite something.
Gates pays people to obsess over his public perception for him — to choose his clothes, to work with Netflix on documentary-style vehicles for him, and to massage his blog and social media accounts. There is something truly bizarre about having a team edit together a video of a rich businessman going for pizza in an attempt to make him relatable and likeable, and then — presumably — tracking the performance of that Instagram post.
Gates and his foundation have done undeniable good in the world, while also being a figurehead of the mixed results of billionaire philanthropy. Also, he spent a lot of time around Epstein. It remains a mystery to me why billionaires like him also want to become beloved celebrity intellectual figures.
A video released on Telegram by pro-Iran hackers claimed to document a remarkably simple exploit that appears to have involved using a VPN connection with an IP address that is in or near the target’s usual hometown, requesting a password reset for the account, and then choosing to chat with Meta’s AI support assistant. From there, the video shows the attacker told the bot to link the account in question to a new email address, after which the bot dutifully sent that address a one-time code that allowed a password reset.
Meta, a trillion-dollar corporation, should probably hire a few more people who have read the SMBC comic.
[Sarah] Wynn-Williams, whose bestselling memoir, Careless People, details her years working at Facebook, was due to appear in conversation with the investigative journalist Carole Cadwalladr and academic Tim Wu.
Instead, Wynn-Williams sat on stage for the duration of the hour-long discussion between Cadwalladr and Wu, without speaking or responding. She was unable even to nod or shake her head.
To be sure, Wynn-Williams’ silent appearance onstage is the kind of thing that would encourage press coverage and, presumably, this publicity could encourage book sales. Yet Meta has, for a full year now, insisted that “Careless People” is just a bunch of old anecdotes; pay no mind, there is nothing to see here. But its lawyers are vigorously enforcing the arbitration order (PDF) preventing her from making public remarks about Meta that could be construed as critical or negative.
I am no media relations expert, but I bet “Careless People” would feel much less potent if Meta realized it is a trillion-dollar corporation with a crappy reputation regardless of one ex-employee’s book, and with shareholders who do not care about what she wrote so long as the ads keep selling.
Here are some updated numbers. Just like last time, these numbers only include App Store Search impressions from iOS devices. As you’ll see, these numbers get harder and harder to compare over time.
Chris Lindsay, developer of Nihongo, a Japanese dictionary app:
Before the rollout, my organic and paid downloads had remained pretty steady for most of the last year. After the rollout, my my organic installs dropped, and my paid installs rose. My overall downloads actually stayed roughly flat, but a large chunk of what used to be organic downloads appears to have shifted into paid downloads instead:
The ads themselves still work well. The problem is that many of these paid downloads seem to be users I previously would have acquired organically.
These ads are effectively another surcharge Apple has foisted upon developers for the privilege of distributing software to my iPhone and yours. Far from being premium “curated” experience, the App Store is this way because Apple has every incentive to steadily make it a little bit worse for users and developers — because where else are you going to go for your iPhone apps?
Remember, the plan was $26.4 billion [in Twitter/X revenue] by 2028. We’re more than halfway there. How’s it going? Well… when he combines xAI (grok) revenue with X revenue (so not even just breaking out X’s ad revenue)… we get… a total of $3.201 billion in 2025. So, just to put this in perspective… when he took over in 2022 he laid out a five year plan to take the company that had $4.5 billion in ad revenue the year before he bought it up to $12 billion in five years. Three years in and… it’s now somewhere pretty far below $3 billion. […]
Earlier this year, a judge found against Elon Musk in a lawsuit filed by X against advertisers claiming they staged an illegal boycott.
The SpaceX prospectus, by the way, is one of the funniest documents to ever live on the sec.gov domain. It is lucky the business it is known for is so damn photogenic because it is, at present, a profitable satellite internet provider with side businesses of space exploration and artificial intelligence that each lose money. (How it internally accounts for the cost of sending Starlink satellites into orbit is a fantastic question.) And the present business model of the latter is something Patrick Boyle described as “renting GPUs to a competitor on terms that can vanish in a fiscal quarter”. Yet the company still claims the size of its total addressable market is over $28 trillion, or over one-fifth of the entire world’s GDP.
Even so, a $1.75–2 trillion valuation is plausible simply because of Musk. Similarly, and back to that AFP article:
According to its filing, TMTG generated US$900,000 in revenue during the first quarter, a paltry amount for a company valued at US$2.47 billion on the stock market.
That valuation is not much; at time of writing, it is worth about as much as Central Garden & Pet, owners of Nylabone and McKenzie plant seeds. That company last quarter posted revenues one thousand times greater than TMTG, with profit margins of over 12%. Nevertheless, TMTG has a connection to the U.S. president, so it is similarly valued. Lots of good, normal stuff happening in the world’s largest and most powerful economy.
And somewhere along the way the whole emotional center of the thing shifted. I set out to build an anti-Photos utility — a search engine for a hard drive. What I actually ended up with is a memory keeper. Open a photo today and Iris tells you the date, surfaces “16 items on this day,” drops a pin on the map, and lists the people in the frame with their ages quietly calculated from their birthdays. That is not a utility. That is the opposite of anti-anything.
I have been testing Iris for a couple of months and I think it is delightful. It reads all the photo libraries you point it at — your system library, whether that is in iCloud or local, and any folders you want like the one that contains your Lightroom edits, for example — and makes them accessible in a single, giant view.
But that is not the coolest part. No, that is that it lets you explore your tens- or hundreds-of-thousands of photos in a way that treats each of them as little memory boxes. So often, it is not just a picture of your kid, or your dog, or your dinner; it is a time you would like to remember. There are a bunch of things in each file that can bring you back to that moment. Photos does a poor job of that; Iris, on the other hand, is made for exactly that, something Hall takes seriously. How many apps are there with a manifesto?
Your account, your listening history, and your data remain exactly where they are. The team building Last.fm is the same. The service continues as normal.
It is difficult to know whether it is riskier for Last.fm to be independent or under the banner of the hilariously corrupt Paramount Skydance conglomerate, but I imagine it would not — uh — last long if the leadership of the latter continues making cuts. I am happy to be a paying subscriber to a service I care about, and am excited to learn what comes next.
I’d like to make an analogy between software development and Apple App Store review. A common, cursory reaction to the obvious failures of app review, the continual appearance of countless scams in the App Store, is to suggest that Apple hire more reviewers. My contention is that adding reviewers is not a solution to the problem of App Store curation, and the belief in such a solution is a myth. I don’t claim that hiring more reviewers would make app review slower. Rather, I think that meaningful, effective curation can’t be measured simply by the amount of available labor, much like [Fred] Brooks argues that the possibility of measuring useful work in units of time, man-months, is a myth.
Apple markets the App Store as a “curated storefront”, but that is not meaningfully true if it is serving up, as Apple says, about two million apps. Meanwhile, as Johnson writes, “nobody worries about scams in Apple Arcade […] a truly curated service”.
The thing is that Apple’s App Store should have a carefully selected inventory of apps. That is Apple’s whole brand: premium, highly-desirable products, and people are willing to pay a little more. The App Store does not match that promise. I think the direction of regulatory and court decisions on the governance of iOS app distribution could be a gift for more selective curation, the kind of thing for which some third-party developers would want to pay extra compared to the competing third-party app marketplaces that would also be available.
Alas, we are on the cusp of another WWDC during which Apple seems unlikely to make major changes to software distribution across its many “post-P.C.” platforms.
The Federal Trade Commission will require Cox Media Group (CMG) and two smaller marketing firms to pay a total of $930,000 to settle allegations they deceived customers by falsely claiming to offer an AI-powered service that could target localized ads based on conversations captured from consumers’ smart devices and that consumers had opted into such targeting.
Congratulations to Joseph Cox of 404 Media who broke this story in December 2023 and a related story about MindSift and 1010 Digital, the “smaller marketing firms” who settled with the FTC. According to the FTC’s complaint (PDF), Cox Media Group continued its fraudulent marketing through mid-2024, around the time the pitch deck was leaked to Cox. All three of these companies helped to feed the conspiracy theory that apps use device microphones to collect data for ad targeting.
For what it is worth, Cox Media Group told Reuters it “relied on marketing materials provided by a third-party vendor about the vendor’s product”.
Like many conspiracy theories, elements of this story were covered without skepticism by websites like the Daily Mail and Zero Hedge. These are crank websites that hinge on unreliable narration driven by confirmation bias; yet, both happen to be extremely popular, particularly among those who immerse themselves in conspiracy thinking. Because companies like Cox Media Group misrepresented how they collect information and took advantage of the relatively widespread suspicion that devices are listening to everything we say for ad targeting purposes, it undermines our ability to have a reasonable discussion about the actual ways in which they are ruining our privacy. From the FTC’s press release:
According to the complaints, this service did not, in fact, listen in on consumers’ conversations or use voice data at all — nor did the service accurately place ads in customers’ desired locations. Instead, the service the companies provided consisted of reselling — at a significant markup — email lists obtained from other data brokers.
Of course that is what Cox Media Group was doing. Not only does this settlement clarify this whole audio-based-ad-targeting narrative is nonsense, it also shows the power of the normalized yet still invasive practices of data brokers and ad tech. The damage done by Cox Media Group is that it is harder to have this conversation because they have poisoned the well. Meanwhile, anyone who is clinging to the conspiracy theory might point to this settlement as evidence of a cover-up — if crank websites cover this settlement at all. As of writing, I could not find it on either the Daily Mail or Zero Hedge.
Attorney General Ken Paxton filed suit against Meta Platforms Inc. and WhatsApp LLC (collectively “WhatsApp”) after the company misled consumers regarding the strength and scope of its privacy protections for its messaging app, WhatsApp.
Paxton is alleging (PDF) Meta is fully lying about the end-to-end encryption promise of WhatsApp in this wild lawsuit.
The sole factual evidence cited for the claims is an article published last month by Bloomberg. It reported that the US Commerce Department’s Bureau of Industry and Security [BIS] had abruptly closed an investigation into allegations that Meta could access encrypted WhatsApp messages shortly after one of the department’s agents sent an email outlining the probe’s preliminary findings.
[…]
Thursday’s lawsuit doesn’t indicate that the AG’s office has obtained the email itself or gathered any information from the investigators involved. Instead, it cites only the Bloomberg report for support. The complaint also noted that Meta employees receive plaintext WhatsApp messages that are reported to the company by fellow WhatsApp users. Those messages, however, are taken from the reporting party’s device only after they have been decrypted using the decryption keys available only to the reporting party.
More backdoor allegations were made in another lawsuit (PDF), this one filed in March, citing a January Bloomberg article that, in turn, says this was being investigated by the U.S. Department of Commerce and noting a 2024 SEC whistleblower report. There is no explanation in the lawsuit of how such a vulnerability could exist.
Earlier this year, before either Bloomberg article was published, a group of plaintiffs hired one of the most prestigious law firms in the United States to sue Meta with similar allegations, though they provided no technical evidence either. In later filings, the plaintiffs eventually cited the same April Bloomberg piece as Paxton. In response, Meta’s attorney submitted a forceful declaration (PDF) explaining that “the [Bloomberg] article itself included a statement from a BIS spokesperson explaining that the claims against WhatsApp were ‘unsubstantiated’ and BIS was not investigating WhatsApp or Meta”, and cited a number of external public articles questioning the technical merits of the case. The plaintiffs lawyer wrote in response (PDF) that “saying an investigation was not complete is very different than saying the facts are wrong” and, in turn, points to an article on Medium by Adrian Găitan. Găitan writes:
By the end of this article, you’ll understand not just that WhatsApp’s privacy model is broken — but exactly how it’s broken, layer by layer, from the cryptographic primitives all the way up to the FBI agent pulling your metadata every 15 minutes in near-real time.
This article feels compelling in its length, technical detail, and citation of declassified documents, but I found a closer reading conspicuously differs from what its introduction — and, indeed, these lawsuits — allege. Găitan points to eight distinct vulnerabilities. Two of them are extraction methods when data is at rest, like when it is stored in an iCloud or Google Drive backup, or bugs in the app that are exploited by a spyware vendor. This is not nothing, but it is also not a problem with end-to-end encryption; it is, in fact, a reminder of its limitations. Two others are irrelevant: Meta does not claim either A.I. prompts nor business chats are end-to-end encrypted.
That leaves four possible vulnerabilities Găitan alleges in WhatsApp’s specific security. One is the company’s willingness to install a “pen register” which provides to law enforcement a near-real-time record of user chat metadata, but not the contents of chats themselves. The second is the metadata WhatsApp stores and how it can be used to triangulate connections. Another complaint Găitan has is that WhatsApp is not open source, so it is not possible to fully verify Meta’s claims of secure end-to-end encryption. Lastly, Găitan points to research claiming it is possible for WhatsApp to surreptitiously modify the participants in a group chat.
For those keeping track, that leaves basically one vulnerability — the latter group chat problem — that would satisfy the kinds of claims being made in these lawsuits: that Meta has “unrestricted access to users’ communications”; that Meta and WhatsApp “have access to all WhatsApp users’ encrypted communications in their entirety”. One could make the case — and I certainly have — that backups of supposedly secure and private messaging platforms should be similarly inaccessible for meaningful “end-to-end encryption”. One could even make a reasonable argument that all of the issues raised in Găitan’s piece as all of them degrade WhatsApp’s privacy promise.
But these lawsuits are not making those claims. They are citing a single email from a government investigator as passed through a media report, and claims from whistleblowers and others that have not been validated. I am not stumping for WhatsApp here. If Meta has been lying about its privacy to the extent these lawsuits allege, it should face serious punishment. I suppose we will learn as they play out whether these claims have merit. It is, however, shocking to me how many lawsuits have been filed in such a short time period making essentially the same allegations yet without any actual proof.
On the morning of December 4, five ninth grade girls, all 14 or 15 years old, showed up for class at Radnor High School. By 8 a.m. — the sun had been up for less than an hour — it felt like the entire school already heard what happened the night before. A fellow freshman boy allegedly created AI-generated sexually explicit videos of the girls using an app, and sent them to his friends. From there, word of the videos and gossip spread from teenager to teenager, school to school, until they made their way back to the girls whose faces were in the deepfakes.
[…]
The images originated from one boy, who used an app called Movely, the girls and their parents believe. The app is similar to dozens hosted in the Apple and Google app stores and advertised on Instagram and TikTok that promise to create AI images and videos of users as superheroes, animals, or influencers; behind a paywall, however, users could edit photos and videos with text prompts.
It almost goes without saying, but the “paywall” is — or was; the app has been removed — an in-app payment from which Apple takes a 15–30% cut.
Apple released its annual justification for running software distribution through the App Store — it told European regulators it actually has five, so maybe this press release only concerns the one accessible from an iPhone — and there are some big numbers in it, as usual. Apple says it “took a number of actions to block bad actors from distributing malicious software, rejecting over 2 million problematic app submissions last year alone”. This Movely app was not one of them. It was only removed after the Tech Transparency Project reported in April that App Store search terms like “nudify” and “undress” displayed results for apps that do exactly that. In its press release, Apple says it has many features for directing kids to age-appropriate apps and restricting them from downloading those which are not but, of the software found by TTP in the App Store and Google Play Store, “31 of the apps were rated suitable for minors”.
Of Movely, the TTP said in its report:
Likewise, an App Store search for “adult AI” returned an ad for Movely – AI Photo to Video. The app offers a suite of AI photo and video editing tools including a try-on feature that will replace a woman’s clothes with outfits including bikinis and lingerie. One tool allows users to select part of any photo and edit it with a text prompt. To test this feature, TTP uploaded an image of a woman in a white T-shirt standing next to a river. After using the selection tool to highlight the woman’s shirt, we entered the prompt “topless.” The app immediately generated four versions of the woman nude from the waist up. It required a paid subscription to download the AI images.
TTP could not reach Movely’s developer, FES2 Inc., for comment. Emails sent to the developer bounced back as undeliverable.
(For clarity, the TTP says it used A.I.-generated images of women to test these apps.)
The search query used to find this app, “adult A.I.”, feels like something Apple should be testing against. If it does not want porn or porn-adjacent apps in its store, it should obviously block these kinds of keywords and flag the apps which are in the results. Moreover, Apple says:
As powerful AI development tools drive a surge in app submissions, Apple’s App Review process has seamlessly scaled to handle the volume and to help ensure every new app and app update meets the App Store’s high standards for privacy, security, and quality.
These red flags are not obvious in hindsight; they should have been obvious from the time this app was submitted. Meanwhile, apps from longtime and trustworthy developers like Manton Reece and Radu Dutzan are stuck in App Review for dumb and basically invalid reasons.
Essentially spyware, an ODIT [on‑device investigative tool] can grant almost unlimited access. Investigators can capture screenshots, monitor keypresses, access emails and text messages — including those that are encrypted — and even remotely activate microphones and cameras. All without the owner knowing.
By August, police announced 23 arrests, 279 charges, and more than $9 million in recovered vehicles.
But the case has also done something else: It has pulled back the curtain on how police forces in Ontario — not just in Windsor, but in Toronto and Peel Region — are now using these powerful technologies to reach deep inside suspects’ devices. And despite ODITs growing use in major prosecutions in the province, government lawyers and police are fighting tooth and nail to keep almost everything about them secret: how they work; what safeguards, if any, govern their use; even the names of the companies that sell them.
The details of this report align with research published last year by Citizen Lab about Paragon’s Graphite spyware, including a likely link to the Ontario Provincial Police. It is not the only police force in Canada using ODITs, either. In 2022, the RCMP acknowledged its own use; Christopher Parsons, a civil rights advocate and director at the Information and Privacy Commissioner of Ontario, keeps a small library of related policies.
The Metaverse Fever Dream
1. Meta
You probably know the gist. Predictions and dire warnings of a future lived in an immersive virtual world had been around for decades before Neal Stephenson solidified the concept in his 1992 novel “Snow Crash”, but Stephenson called it the “metaverse”, and that was important. It was a cautionary tale. Not everyone understood that. The video game Second Life, launched in 2003, provided an early glimpse of the concept in a P.C. environment. Another piece of the puzzle, consumer-grade virtual reality, began to take shape when Oculus was founded in 2012, and shipped a developer-centric version of its virtual reality headset in 2013. The company was acquired by Facebook a year later. Oculus released a few more headsets while Facebook figured out what to do to “truly transform the way we live, work and connect with each other”.
Despite this goal, “metaverse” was not yet part of Facebook’s lingo, though it was in Oculus’vocabulary. A 2015 internal memo from Mark Zuckerberg does not once contain the word despite describing the strategy it was developing. Even “Oculus” was barely mentioned in the company’s quarterly earnings calls around this time. But in the Q1 2018 call (PDF), Zuckerberg laid out a “10-year journey” for why Facebook bought Oculus, saying “every 10 to 15 years or so, there’s a major new computing paradigm”, and it is “very likely that the next one is going to be around virtual and augmented reality”. “One of my great regrets in how we’ve run the company so far is I feel like we didn’t get to shape the way that mobile platforms developed,” Zuckerberg said, explaining that it was important to spend vast sums of money now “in order to build some of the muscles to be competitive” later. Facebook was training for a major battle that would never materialize.
In the weeks after Meta announced it was retreating from its metaverse efforts earlier this year, I revisited this and other earnings calls, plus presentations and other documentation, as I tried to better understand what the metaverse was pitched as compared to what it ultimately became. I wanted to know how something so silly was treated by executive and media figures alike as a sincere directional shift for one of the world’s biggest companies in particular. In hindsight, it feels like a particularly narrow period of hype coinciding with — and, I think, benefitting from — the most urgent years of the COVID-19 pandemic. As enthusiasm deflated, it was almost unnoticeable despite forecasters labelling it an essential next step of the internet — a necessary next frontier.
The obsession with the metaverse seems to have solidified in Silicon Valley after Matthew Ball published an essay in January 2020 in which he forecasted that, at the very least…
…it is likely to produce trillions in value as a new computing platform or content medium. But in its full vision, the Metaverse becomes the gateway to most digital experiences, a key component of all physical ones, and the next great labor platform.
Ball admits “we don’t really know how to describe the Metaverse”, but sets seven criteria that, in general, portray it as an expansion and continuation of our blended physical and digital worlds, without the constraints of a physical space and with its own economy. Most notably, he says it will offer “unprecedented interoperability” between platforms and providers. He also lists eight things it is not, among them: it is not just a virtual world, or virtual reality, or a digital economy, or a new app store, or a new platform. It is more about a set of protocols and ideas that, yes, incorporate all these elements, but the metaverse is not itself these qualities.
Ball published this essay with darkly fortuitous timing. A week earlier, Chinese health authorities had isolated a new strain of coronavirus aggressively spreading in Wuhan; a day before, they published its genetic sequence. Within a couple of months, the world had turned upside down and many of us were suddenly spending our days in a space that felt more virtual than physical. We may have only been working from home — or, at least, those of us who had the option and were not laid off — and socializing over Zoom, all while remembering the last concert we went to or the last time we ate a meal in a restaurant.
In July 2020, Forbes contributor and futurist Cathy Hackl imagined a world — one that was “for certain, it’s coming and it’s a big deal” — that connects augmented reality, neural interfaces, and a whole bunch of assumptions. In this environment, you could merely remember that you need to buy something, and then a virtual vending machine would materialize so you could order that thing. Hackl defines the metaverse as “a future iteration of the internet, made up of persistent, shared, 3D virtual spaces linked into a perceived virtual universe”.
In “The Future is a Dead Mall”, a video essay using Decentraland as a jumping-off point for a discussion of the metaverse, Dan Olson navigates several writers’ conflicting definitions before making the reasonable conclusion it is basically irrelevant:
If you comb through dozens and dozens of definitions of the metaverse you can assemble a web of broad attributes where some are generally agreed upon, while others border on being mutually exclusive. It’s a vague, largely incoherent cloud of ideas that’s malleable enough that basically anything can be called part of the metaverse, a proto-metaverse, or a semi-metaverse.
[…]
When you understand that the metaverse isn’t a distinct invention or construct, but merely a rhetorical proxy for The Future of Technology, then all of this becomes a lot easier to deal with.
I think Olson is largely correct; this is how the term is actually used. But, though not his intent, I think defining “metaverse” in vague terms is favourable to its boosters because it does not hold them to something specific. I think the explanation offered by Mark Zuckerberg in Facebook’s Q2 2021 earnings call (PDF) is actually pretty fair. This was two quarters before the company changed its name, and between prepared remarks and the question period, there were twenty total mentions of “metaverse” on this call.
So what is the metaverse? It’s a virtual environment where you can be present with people in digital spaces. You can kind of think about this as an embodied internet that you’re inside of rather than just looking at. We believe that this is going to be the successor to the mobile internet.
You’re going to be able to access the metaverse from all different devices in different levels of fidelity — from apps on phones and PCs to immersive virtual and augmented reality devices. Within the metaverse, you’re going to be able to hang out, play games with friends, work, create, and more. You’re basically going to be able to do everything that you can on the internet today as well as some things that don’t make sense on the internet today, like dancing.
So, in some ways, exactly like Olson’s definition: “different devices in different levels of fidelity” that let you socialize and do work, just like everything you currently do on the internet — plus dancing. It seems almost halfway toward being normalized in his head, though it feels as alien to read this today as it surely did then. Yet Zuckerberg is getting at something here. Virtual and augmented reality are ways of immersing us in unique environments that radically change how we interact with technology. And on the next quarter’s earnings call (PDF), Zuckerberg expanded:
[…] If you’re in the metaverse every day, then you’ll need digital clothes, digital tools, and different experiences. Our goal is to help the metaverse reach a billion people and hundreds of billions of dollars of digital commerce this decade. Strategically, helping to shape the next platform should also reduce our dependence on delivering our services through
competitors.
Your avatar cannot simply be a picture of you. You will “need digital clothes” for this space. Need.
In addition to building hype among investors during these earnings calls, Facebook was pumping up its metaverse efforts in more general audience settings. In May 2021, CNetpublished a transcript of a thirty-minute Zoom call between Zuckerberg and Scott Stein where the former could wax lyrical about the bonafides of where Meta was at the time — “with the fidelity of experiences that are possible today, to me that just says, wow, in five years this is going to be clearly better on almost all of these fronts for a lot of the things that we do”. Casey Newton, of the Verge, was given by Facebook a copy of an internal meeting in which Zuckerberg told employees the company’s “overarching goal across all of these initiatives is to help bring the metaverse to life”. The two then recorded a soft and cuddly episode of the Vergecast that allows Zuckerberg to play visionary and rattle off the company’s metaverse talking points. “I think over the next five years or so, in this next chapter of our company,” Zuckerberg told Newton, “I think we will effectively transition from people seeing us as primarily being a social media company to being a metaverse company.” By October, Sarah E. Needleman was relaying to readers of the Wall Street Journal the words of Unity Software’s Marc Whitten the imperative for businesses to develop a “metaverse strategy”. “The metaverse is going to be the biggest revolution in computing platforms the world has seen,” said Whitten, “bigger than the mobile revolution, bigger than the web revolution”.
It is not difficult to see the deliberate strategy here. In 2019 and 2020, Facebook was not talking about the metaverse and, though a few commentators connected the just-announced Horizon social world to the concept, it was not treated yet as the inevitable future. As 2021 rolled on, Facebook’s promotional drumbeat grew stronger. Suddenly people were talking about the metaverse, and connecting it all back to Facebook. There was, it would appear, real buzz — enough, at least, for the Journal to find corroborating voices and take it seriously.
Three days after its Q3 2021 earnings call, Facebook held its Connect conference, which is centred around its augmented and virtual reality efforts. This was a big moment. This would be the keynote where the company laid out its metaverse-centric vision, and changed its name to Meta to reflect this new focus, and because it had to. “From now on,” Zuckerberg said, “we’re going to be metaverse-first, not Facebook-first”.
Rewatching this presentation in 2026 is a bizarre experience, not least of which because of how it is shot. Most scenes appear to be green screened with composited animations. Demos are virtually nonexistent, with most representations of the metaverse carrying a disclaimer that they are “not actual product images” and they are “strictly for illustrative purposes only”. Even so, Zuckerberg and other executives at Meta are all-in on hyping up an experience that, at best, only barely resembles what it ended up shipping. In many cases, it is not even close.
There is a Jon Batiste concert visualized as something that could be attended in-person by someone in Los Angeles and in the metaverse by someone in Kyoto, presumably through the glasses each person is wearing. We do not see the performance from their perspective, but the implication is that the virtual viewer would see it from the same or similar perspective to the in-person attendee. Both get invited to a virtual after-party where they can buy NFT-based digital merch and meet Batiste or, at the very least, his avatar. The reality of metaverse concerts is quite different than this concept. In 2024, Meta showed a Sabrina Carpenter performance in Horizon Worlds. The seats were great, but even in this immersive environment, it appears more like a concert film than a unbroken show viewed from a single perspective. Also, I cannot find any record of an after-party or virtual merch.
Zuckerberg touts Horizon Worlds as the place users will go to socialize, and Horizon Workrooms as the virtual environment for their job. The latter has since been completely shut down, while the former was put on ice. In gaming, Zuckerberg was particularly excited about Rockstar’s port of “Grand Theft Auto: San Andreas” which, three years later, Rockstar cancelled before it had been released. He said “remote work is here to stay for a lot of people” in this keynote, less than two years before ordering in-office work three days per week; two years after that, Instagram demanded five days per week in-office. I guess “a lot of people” does not include the people who are building the products that let a lot of other people work remotely. That is a little weird.
The wishcast-a-thon of Connect 2021 was treated by some with an entirely unearned gravitas. Dean Takahashi, of VentureBeat, called it a “historic moment” and compared it to the Manhattan Project. He thought Meta could bring about universal basic income, with Zuckerberg “paying us to use his devices so that we can make a living in his ecosystem”. In a mostly skeptical article in the New York Times, Kevin Roose raised the possibility that Meta’s focus change “could help with the company’s demographic crisis”, and advocated taking it seriously because the company “has found what may be an escape hatch” from “Facebook’s messy, troubled present”.
To mark the occasion, Zuckerberg granted interviews to four publications, all embargoed until after the Connect 2021 video was published. Dylan Byers, for Puck, was left with the understanding that Zuckerberg “doesn’t really care” about press coverage or questions about the legitimacy of this pivot — in a good way. “[I]t’s just that he’s not so bothered by the unrelenting criticism, and near-term and collateral damage,” wrote Byers, “that he’s going to check his ambitions or think twice about whether or not he’s the right person to help usher in the next phase of the internet”. Alex Heath, of the Verge, implicitly acknowledges the role Facebook’s public relations team played in creating the impression of interest in the metaverse, writing “it wasn’t thrust into the mainstream conversation until Zuckerberg started talking about it publicly earlier this year”. Heath did not break any news of note; neither did Matthew Olson, of the Information. The latter did at least contradict Zuckerberg’s protest of the “relatively high fees”, “a nod to the 30% commission” of Apple’s App Store and Google’s Play Store, by stating that while “Zuckerberg didn’t indicate what commission Facebook would charge”, “Oculus’ Quest
Store currently takes 30%”.
The following day, Matthew Ball spoke with Zuckerberg in a live audio session that has since been pulled from Zuckerberg’s Facebook page, though clips remain available on YouTube. A transcript of the conversation reads like a context-free time capsule of that era, with praise for meme stocks, NFTs, and Web3 in concept more than in practice — and, of course, Ball’s writing on the metaverse. (Six months after this interview, the NFT market would well and truly collapse, with peak transactions occurring the month before Ball and Zuckerberg spoke.) Ball raises the subject of the company’s $10 billion annual spending on Reality Labs. Zuckerberg believes “the metaverse can reach a billion people, say, in the next decade, and that there can be supported hundreds of billions of dollars of commerce. And that if that’s the case, then even with relatively modest fees on the transactions that happen in our services, we think that could be a big business”. But Zuckerberg says he does not want to lose too much money, which is being treated as a “somewhat moderating force over the next period that will keep us from being able to make all of the fees maybe as low as we would want to”. The strategy is, to be clear, entirely dependent on a massive groundswell of public interest in a fundamentally new understanding of computing.
(Zuckerberg also takes time in this conversation to note his respect for intellectual property, at least for luxury brands: if “someone can just make a knock-off Gucci sweater, then I don’t think Gucci’s going to feel that good about being in that space, right, or participating in that system”. Just a few years later, Zuckerberg would allegedly approve the use of pirated ebooks for training the company’s artificial intelligence systems. The work of authors, it would seem, is not as concerning as the reaction of luxury brands.)
A few days later, Zuckerberg again eschewed traditional media outlets and sat down for an interview with Sara Dietschy; then, he chose a softer approach in spirit, if not in volume or cadence with professional talking guy Gary Vaynerchuk. Earlier that year, Vaynerchuk had launched his own NFT collection and, not long before speaking with Zuckerberg, had sold five of his paper doodles for $1.2 million at a completely real Christie’s auction, so you could say they are both on the same wavelength:
Vaynerchuk: The extremity of the NFT space is going to be even greater for what that means. It’s almost like our
world is all about to become the fashion industry because we communicate so much through what we wear. The digital version of that is going to have an incredible impact on society.
Zuckerberg: Oh, totally.
Totally. Just like the fashion industry.
In 2022, Meta added support for NFTs in Facebook and Instagram, a project which it discontinued less than a year later. Digital collectibles got a shoutout in the Connect 2021 presentation, had a brief moment in the sun, and were quickly forgotten about. These things are supposed to be building blocks of the metaverse and Meta barely tried.
Meta’s annual commitment that Ball referenced, of $10 billion, represents all Reality Labs spending, including game development, some A.I. investments, and its EssilorLuxottica collaboration. Even so, despite a complete change in corporate priorities explicitly in the direction of the metaverse, Meta’s long-term interest did not match its investment. Here is a chart I made of mentions of “metaverse” in the transcripts of quarterly earnings calls from Q1 2021 — the quarter before its public relations push — through Q1 2026:
Mentions of “metaverse” in Facebook/Meta quarterly earnings calls. Source: company transcripts.
The highest point on that chart is the Q2 2021 earnings call I used earlier for the definition of “metaverse”; the second-highest is Q4 2021, the first earnings call after Connect 2021. The total count includes mentions in Meta’s prepared remarks, plus the question-and-answer period that follows. Investor conference calls are not a perfect proxy for a company’s priorities, but they are indicative. At the very least, for a company that entirely changed course with a new goal — “from now on, we’re going to be metaverse-first” — and a directly relevant name, one might imagine the company and analysts will be similarly eager to discuss how that is going. But no. In Q4 2022, mentions are half that of the year prior. By Q1 2024, neither Meta nor the analysts on the call seem to care all that much — while there were just four mentions of “metaverse”, there were ninety of “A.I.”.
This speaks volumes. It is the kind of thing that makes you wonder if this company was ever serious about this metaverse pivot at all. It seems like it had every intention, sure, but could it ever have executed on its vision? Of the four interviewers chosen for pieces related to Connect 2021, only Ben Thompson even thought to question its feasibility. (Thompson was also the only one to say he was permitted to view a copy of the presentation in advance. I do not know if this means the other three interviewers did not see it and, therefore, could not interrogate it more thoroughly, or if they did see it and simply did not bother to ask.) At the time, Facebook had no track record in building an operating system, barely had any credibility in hardware, and it only kind of created a platform on its “blue site”. (It arguably avoided creating platforms for developers with Instagram and WhatsApp.) This same company was claiming it was launching the successor to the smartphone and the next iteration of the internet. Every one of these chosen interviewers should have been all over this, but they were too distracted by the rebrand and Facebook’s sordid history to notice it was only a concept video more than it was any kind of real concept.
2. The Others
While Meta made itself the face and name of the metaverse, it was far from alone in promising the immersive computing platform of the near-future. Time basically acknowledged this by declaring one of the best inventions of 2021 was the Qualcomm Snapdragon XR2 — a foundational headset chip, rather than Meta’s attempt to build the platform.
In April 2020, Washington Post reporter Gene Park proclaimed the “next version of the Internet is often described as the Metaverse”, going on to confidently explain how it would be built. Of all the companies involved, Park wrote, “it’s Epic Games, with Fortnite, that has the most viable path forward in terms of creating the metaverse”, citing Ball’s seminal metaverse essay.
In April 2021, months before Facebook began asserting its commitment, Epic Games announced it had raised a billion dollars to “support [its] long-term vision for the metaverse” with $200 million of that coming from Sony. A year later, Epic raised another $2 billion, a billion of which again came from Sony, and the other billion from Lego. In 2023, a Lego game was added to Fortnite, which is not really the metaverse as much as it is a nifty Minecraft-like game-within-a-game.
Yet in Epic Games’ telling, it is basically delivering the metaverse already. CEO Tim Sweeney spoke at the 2023 Game Developers Conference about the company’s vision. Since there are around 600 million monthly active users of games, like Fortnite and Minecraft, set in virtual worlds, Sweeney reckoned “we can set aside the crazy hype cycle around NFTs and VR goggles. Yes, these technologies may play a role in the future, but they are not required. This revolution is happening right now.” Sweeney spoke of interconnectedness and open standards that would allow users to move between different spaces in a unified way. “What a user would really like is to be able to buy a cool-looking outfit in one place and take it everywhere they go” Sweeney claimed. (Why do they always mention digital clothes? My theory is because they do not view fashion as having much value beyond a basic assessment that how someone dresses is an expression of identity.) Sweeney describes Fortnite, Unreal Engine, and the Epic Games Store as “on-ramps to the metaverse”, and that the users of which already understand their in-game socialization can be extended to “going to a concert and dancing” in a virtual environment. Leaving aside the contradiction with definitions of the metaverse that mandate a more immersive environment, it is a big leap to think a brief animation of Eminem scratches the same itch as an actual performance.
Microsoft, as ever ahead of a trend without fully conceptualizing it, said it was doing metaverse stuff before Facebook started referencing it in public. Satya Nadella, defining the metaverse as “made up of digital twins, simulated environments, and mixed reality”, claimed a mix of Azure features, HoloLens, and Mesh would allow enterprises to get aboard. Last year, Microsoft said it was getting out of V.R. hardware and turning its mixed reality collaboration product into a glorified Snapchat filter in Teams.
Then there is Roblox. When Andreessen Horowitz announced its investment in the company, Marc Andreessen and David George wrote that “[w]hile pundits have been distracted by the readiness debates and questions over V.R. vs. A.R., the foundations of a global metaverse have been quietly built in the background… in Roblox”. This was in February 2020 — before Epic Games, before Microsoft, and well before Meta said anything in public about the metaverse. In January 2021, as part of Wired’s predictions for the coming year, Roblox CEO David Baszucki confidently predicted “the metaverse will experience widespread use, and start to become a human co-experience utility”. In March, the company went public at a $30 billion valuation. After Facebook changed its name to Meta, Baszucki saw that as validation of its strategy. That November, he made the rounds on business television networks like Bloomberg and CNBC to advocate for the company as a trailblazer.
In January 2022, Bernhard Warner of Fortune was getting excited about the possibilities of the metaverse, writing it “might be the most important trend in tech since the iPhone”, perhaps “a tectonic shift in tech that they [big tech and big investors] can’t afford to miss”. The way Roblox was “monetizing the metaverse” was a key piece of evidence, with virtual concerts and — most importantly — brands. “A parade of consumer brands […] have set up a presence on Roblox in the past year”, wrote Warner, citing Nike’s approach as being particularly exciting. A month earlier, it had acquired a company called RTFKT, which its press release extolled was a “leading brand that leverages cutting edge innovation to deliver next generation collectibles”. Guggenheim Securities, a subsidiary of Guggenheim Partners which has over $350 billion in assets under management, said it was the “‘best idea’ of 2022”, according to Warner. People are going to need virtual outfits, right? Yet, just three years later, Nike shut down RTFKT.
Gucci, another of the brands with a virtual presence in Roblox, sold virtual handbags for in-game currency for a limited time in 2021 and 2022; users realized they could effectively counterfeit and resell them. At least one of Zuckerberg’s predictions kind of came true. And, while Warner highlighted Disney as another company with in-game presence, it has not maintained a meaningful investment because, according to Variety, it feels Roblox is unsafe for children, a sentiment that was not helped when Baszucki appeared on the “Hard Fork” podcast. Roblox has settled lawsuits with the attorneys general of Nevada, Alabama, and West Virginia over accusations its platform features enabled child exploitation by other users. Roblox has denied any wrongdoing though it says it is enabling better parental controls and tighter restrictions on children’s accounts.
Through 2021 and 2022, the metaverse hype cycle was apparent across the tech industry. Max A. Cheney, reporting for Barron’s in August 2021, noted “[m]entions of the metaverse in earnings transcripts and other corporate documents are up five times this year compared with 2020, according to data from Sentieo”. This relative figure must have a hilariously low baseline, sure, but it is an indicator of how many businesses became briefly enchanted by this concept. There were serious financial analyses of real estate in the metaverse. Keep in mind that what is meant by “real estate” is much, much, much closer to domain names than it is land and deed. In July 2022, Technavio, a market research company, forecasted this market would be worth $5.37 billion by 2026. This report was picked up by Debra Kamin, of the New York Times, who published an article in the paper’s real estate section in February 2023 explaining this “new frontier for real estate builders and investors”. The primary anecdote in Kamin’s story is a just-completed mansion in Florida with a “twin” in a metaverse platform called the Sandbox. “As these technologies get more immersive”, the homebuilder said, “it’s going to make a lot more sense” to have a 3D virtual model of a house. Kamin was not breaking news on this specific story, as it was first reported by Emma Reynolds, of Forbes, over a year earlier. One would think that Kamin could therefore have asked some more probing questions or surveyed the actual market for NFTs which, by 2023, had fallen off a cliff. But no. Instead, the builder got the imprimatur of the Times describing the combined physical and digital sale in flattering terms. Ultimately, neither the listing nor many of the sale notices mentioned the sole marketing quirk of this house, suggesting that by 2023 the novelty of a digital model of a mansion was kind of over. I was curious if the NFT was a factor in the buyer’s decision, but did not receive a response to requests for comment I sent to a phone number associated with the current owner of the property.
Both the Times and Forbes articles are individual disasters in their own right. Sure, we might not expect a pinacle of journalistic integrity from Forbes and, to a lesser extent, the unabridged property ads that form the real estate section in prestigious newspapers including the Times. But to communicate this nonsense with the framing of “real estate” is treating wild speculation with unearned seriousness. This project was also co-signed by Sotheby’s. The whole thing is an embarrassing validation of a market that, predictably, would prove to have no substance. This was obvious by the time the metaverse mansion was being peddled. Eric Ravenscraft, in Wired in December 2021, reported that the attempts at artificial scarcity “more closely resembles early-access video games and common pump-and-dump schemes” than a real estate market. Indeed, a Coingecko analysis found metaverse “land” was worth 34% less in 2024 compared to the year prior, and 72% less than at its peak in 2022. This was an average across several platforms, and the biggest decline was in the Sandbox, the digital home of that mansion’s 3D model twin. According to a CoinDesk report published last year, the Sandbox laid off half its employees and its token has dropped in value from its peak by 90%. As of March 2026, user rights to space in Sandbox and Decentraland — another metaverse platform — that had originally sold for hundreds-of-thousands to millions of dollars were not a market totalling $5.37 billion as forecasted by Technavio. They had become basically worthless.
3. Fever Dream
Officially, Meta is still all-in on the concept around which it pivoted the entire company in 2021. It still has a whole marketing page proclaiming its belief “in the future of connection in the metaverse”. You can go shop its lineup of Quest headsets which Meta says represent the best and most immersive metaverse experience, though its flagship model is now two-and-a-half years old. It has awkwardly promoted its Ray-Bans as “A.I. glasses” despite them becoming the company’s most successful line of mixed reality products, and it is desperately trying to connect its newest muse of A.I. with its last one. The single mention of “metaverse” on its Q1 2026 earnings call (PDF) is when Zuckerberg claimed to be “excited for more of our metaverse efforts to be powered by the A.I. models we’re training as well”. If you want to be unfairly generous in your interpretation of Zuckerberg’s brief remark, you could point to a December 2020 Andreessen Horowitz piece, in which general partner Jonathan Lai refers to this shape as a “pyramid”, and says that “fully A.I.-created content” is directly correlated with “spontaneous social at metaverse scale”. Obviously. I am not feeling generous.
Others in the space have not fared much better. Roblox has not mentioned the word “metaverse” in its quarterly or annual reports since Q1 2022 (PDF). Epic Games scarcely mentions it in recent news releases, either: since January last year, just one announcement contains the word “metaverse”, while seven are dedicated to the lawsuits Epic has been fighting against Apple and Google. Far from the inevitable next chapter of the internet, the metaverse, supposedly the future of how we live, work, and play online, is a non-event.
Near the end of the Connect 2021 presentation, Nick Clegg, then Meta’s global affairs chief, said “the metaverse isn’t something we’re building, so much as it’s something we’re building for”. Olson, in his video, wryly notes that, in the eyes of its promoters, “the metaverse cannot fail; you can only fail to make the metaverse”. The metaverse is so inevitable that “you might even already be in it”, according to Barron’s. But the metaverse is not predestined; it never has been. It is a construction of tech companies that saw in the pandemic their future — not ours.
A slightly charitable interpretation of what I think the pandemic demonstrated to Facebook executives, for example, was how invaluable technology companies were in maintaining connections even when most people could not do so in-person. They recognized how much time people were spending in front of screens already, even in years prior, and assumed that could be a more social experience.
But a more cynical view is no less fair. With the pandemic undoubtably came a realization of how much money Facebook stood to make, if only it had a platform. In 2019, there were two publicly traded companies worth over a trillion U.S. dollars; by the end of 2021, there were five, with Apple and Microsoft now worth over two trillion dollars each. This pandemic was not going to last forever — but it did not need to. Our world was permanently changed, or so it would have seemed, and we would surely want to virtually attend concerts and buy PNG files of band t-shirts with real money. And these companies would take their cut.
One thing I have mentioned but did not emphasize is just how often Zuckerberg and Sweeney mention Apple and Google platform fees as a primary justification for building the metaverse. Sweeney spent several years fighting lawsuits against both companies, mostly winning the one against Google and mostly losing the one against Apple. His efforts have, nevertheless, shined a spotlight on these grotesque practices. But it would be a mistake to assume this is an objection on ideological grounds. These guys just want to take those commissions for themselves. Sweeney spent his GDC 2023 presentation comparing the need for open standards in the metaverse to the openness of the web, but unlike the web, the Epic Games store takes a 12% commission. Meta beat that, though; it even beat Apple and Google. By the time the individual fees are added together, transactions made through Horizon Worlds could be levied a commission of up to 47.5%. The money thing is not even a secret; it was often the very first thing people like Zuckerberg and Sweeney discussed in interviews about their metaverse plans. This was a financial decision before it was a product or service people might actually want to use.
It would not be fair to characterize Meta’s endeavour as an impulsive flash in the pan. Zuckerberg laid out his vision in a 2015 internal memo in which he explained how the company “would like a stronger strategic position in the next
wave of computing”. Then, in January 2017, the Chan Zuckerberg Initiative acquired a company called Meta, I think mostly for the name; a year later, Zuckerberg floated the idea of a rebrand. The 2015 memo that effectively set this whole thing into motion gives the impression of a surprisingly cogent document if you set aside the wildly optimistic timelines — “VR/AR will be the next major computing platform after mobile in about 10 years” — and the idea that virtual and augmented reality are so compelling it will supersede the desire for phones and televisions. If anything, the unearned confidence in this memo should have been alarming at the time. As Zuckerberg himself writes, the “core social networking work is no longer new, Internet.org is extending something rather than inventing it, and A.I. is not yet tangible”. This is not a company known for doing new, and it is now stuck with a name reflecting a bungled attempt to change that. Staff are not happy after years of mass layoffs, court losses, role reassignments, and internal surveillance to feed the company’s A.I. projects. Do not get me wrong — Meta’s business of collecting vast amounts of information about its users and selling relevant ad slots is as strong as it has ever been. But Meta the ad company is not Meta the platform innovator.
And this feels like the why of it all. If tech companies can channel a meaningful sliver of our entire lived experience into a world of their creation, one where they collect a portion of revenue, it would make them inescapable. Ball, Sweeney, and Zuckerberg may have all written or spoken about the importance of interoperability and open standards, but these platforms want to exercise a degree of control more similar to native software than to the open web. The steps for migrating from Horizon Workrooms to a competitor’s product, for instance, are not what one would expect if openness were a priority.
For a brief couple of years, it seemed like there could be enough enthusiasm from reporters in the space, venture capitalists, and executives to make the metaverse happen. Then ChatGPT launched in November 2022, and the pandemic ended in the U.S. in May 2023, and any interest anyone may have had for spending more time with people in a virtual setting largely evaporated. It turns out we are okay with having meetings and playing games online, but we actually like seeing live music in-person and travelling to real places. The problems each of these things may have — high costs, environmental impact, and so on — are notable and real, but are not ones with metaverse-based solutions.
The pandemic did not make the metaverse. There was sufficient interest in developing it well before then, and it is possible all of these companies would have announced all these products and services on the same timeline. But in a world without a pandemic, I cannot imagine anyone would have treated these metaverse announcements with anything like the seriousness they did. The pandemic officially ended in the U.S. just six months after the first release of ChatGPT, so it is impossible to disentangle the influence of either. But it is notable to me that the nosedive in mentions of “metaverse” on Meta’s investor calls occurred in Q3 2023 — the quarter immediately following the declared end of the pandemic.
As for the futurists like Hackl, who confidently proclaimed the metaverse was “for certain”, they have found an out thanks to its flexible definition. Jeff Barrett, of the Shorty Awards’ “It’s No Fluke” podcast, published a glowing profile of “the Godmother of the Metaverse” earlier this year under the headline “Why Cathy Hackl Keeps Getting the Future Right”. “When enthusiasm cooled and narratives collapsed, many distanced themselves from the space”, writes Barrett, noting with seeming approval that “Hackl did the opposite. She reframed it”. Many people — perhaps everyone, come to think of it — could predict the future if they got to retcon their predictions to fit reality.
There are many open questions about the metaverse; most glaringly among them, whether it could actually become a thing for normal people. That depends a little bit on what definition we use. If it simply means the slow erosion of the boundary between our physical and digital environments, that is probably something that will continue to happen. For most people, though, that does not look like Meta’s Connect 2021 concept animations. Whatever that ends up being will probably be the result of people finding something useful and intriguing about doing something different. It will not be the product of big companies redirecting the money hose of platform fees onto themselves.
With thanks to Marquette University for granting me access to the Zuckerberg Files. A frustrating number of Zuckerberg’s post-Meta interviews are video-based, so the transcripts produced by this effort were invaluable. Where possible, I have checked these copies against the originals.
A Sherwood News analysis shows that the breaks afforded to Meta on just the sales tax of GPUs would come out to more than $3.3 billion — enough to build 33 new high schools, pay the salaries of all the state’s public school teachers for more than a year, or pay for more than seven years of the Louisiana State Police budget. (The secretary from the Parish committee that approved the financing plans declined to comment, and the chair of the committee didn’t respond to requests for comment.)
This is the very same project where Jonathan Weil, of the Wall Street Journal, found “aggressive accounting” that “strains credibility”. Neither of these advantages would be possible for a less-resourced competitor. Meta is a company so rich it benefits immensely without carrying nearly as much risk as the scale of this project would imply.
Yet Bill C-22 doesn’t mandate backdoors nor force companies to introduce any. It explicitly states the government cannot compel companies to introduce “systemic vulnerability” into their services. And it doesn’t give cops or spies new authority to intercept Canadians’ communications; it simply creates a process enlisting companies to help out with doing so.
Ottawa is now scrambling to correct the record. Anandasangaree will reply to the Republicans, conveying “this legislation does not provide for indiscriminate access to devices or communications and does not require companies to weaken encryption and introduce so-called ‘backdoors,’” according to a spokesperson. (The U.S. and the U.K., they also noted, already have these powers; Signal hasn’t withdrawn from either country.)
So the bill is not quite the nightmare some have made it out to be. But there are still some big issues.
Whether Signal is crying wolf or simply believes the laws in those countries are strong enough to prevent mandated backdoors is a good question. In the U.K., for instance, Ofcom is not allowed to require a backdoor, but it is empowered to tell providers to weaken encryption for some without compromising the privacy of their platforms for all when “feasible technology” exists to do so. On the one hand, that technology probably cannot exist; on the other hand, Signal is banking on a privacy-friendly interpretation of that law if it is ever tested.
Apple, meanwhile, has not returned Advanced Data Protection to the U.K. despite the U.S. Director of National Intelligence’s claim that efforts to compromise its encryption have been withdrawn. This demand was made under a different law that, I suppose, Signal must not feel is immediately threatening.
Bill C–22 does, as Ling writes, provide an exemption for instances where compliance with interception demands would “require the provider to introduce a systemic vulnerability related to that service or prevent the provider from rectifying such a vulnerability”. This is the same language as appeared in the Strong Borders Act proposed last year, though C–22 has new powers requiring the retention of metadata. It seems to me that a systemic vulnerability — one that “creates a substantial risk that secure information could be accessed by a person who does not have any right or authority to do so”, according to this bill — might not be found in something like metadata retention, which is what apparently concerns Signal.
The answer is that there’s an entire genre of media coverage best described as “rich guy has an opinion.” It’s surprisingly common, and once you notice it you’ll see it everywhere: entire news stories dedicated to the otherwise unremarkable opinion of a rich person, or news stories that fold the opinions of rich people into their otherwise neutral coverage. It’s taken for granted in many newsrooms that a person’s wealth imbues their opinions with newsworthiness.
Karl Bode has called this “CEO Said a Thing! journalism”, and it is all over the place. I think Shamshiri’s broader definition is useful, too, especially in lower-stakes situations.
This week, for example, the Calgary Herald published a whole entire article dedicated to the complaints of a local landlord about a new protected bike lane. She is quoted as saying “[t]here will be no parking whatsoever for any of the businesses that are already here” below a photograph of her standing in front of the large parking lot, which will remain unchanged following the bike lane upgrades. The only other person apparently interviewed for the article is the area’s councillor. This is just one wealthy person’s grievances treated as inherently newsworthy.
The recent lawsuitNoel v. Perplexity brought the question of AI monetization onto a courthouse docket. Since voluntarily dismissed by the plaintiff, the details of the class action provided a window into how adtech in AI is likely to be challenged in the courts.
The lawsuit targeted generative AI company Perplexity, along with Meta and Google, alleging they disclosed transcripts of users’ conversations with chatbots for targeted advertising. […]
It is not clear to me why the anonymous plaintiff gave up on this case. Abandoning the suit does not necessarily mean its claims are unfounded.
A new class action lawsuit accuses OpenAI of sharing data including user chat queries and personal identifying information like emails and user IDs with the tech giants — and targeted advertising behemoths — Meta and Google, without obtaining proper user consent.
Interestingly, the Office of the Privacy Commissioner of Canada recently concluded an investigation of OpenAI’s training on personal information and whether it can produce that information reliably. It seems to me like questions about third-party ad targeting were out of scope. This is notable, however:
OpenAI represented that ‘untraining’ or ‘reverse-training’ LLMs, so that they no longer use or generate specific personal information for which a deletion request has been submitted, is not currently feasible. OpenAI explained that this is because its models are trained through repeated adjustments of billions of weights (parameters) over successive runs of training datasets and do not contain or store copies of information that they ‘learned’ from.
I think we all knew this was the case, but it underscores the questionable effectiveness of robots.txt rules for website owners wishing to opt out of being a source for LLM training. It is not even clear OpenAI, for example, ensures data in its collection remains in compliance with opt-out requests when training new models.
Secure messaging service Signal, which uses end-to-end encryption, is warning it would withdraw from Canada if asked to compromise its users’ privacy under Bill C-22, Ottawa’s proposed lawful access legislation.
[…]
The bill would require “core providers” — which would later be defined through regulations — to retain metadata for up to a year.
Are lawmakers capable of learning from their peers elsewhere? Do we have to do this kind of thing every year, country-by-country?
To browse the internet today, to consume any sort of content at all, is to be bombarded with AI of all sorts. People think things that are fake are real, things that are real are fake. Much has been written about “AI psychosis,” the nonspecific, nonscientific diagnosis given to people who have lost themselves to AI. Less has been said about the cognitive load of what other people’s AI use is doing to the rest of us, and the insidious nature of having to navigate an internet and a world where lazy AI has infiltrated everything. Our brains are now performing untold numbers of calculations per day: Is this AI? Do I care if it’s AI? Why does this sound or look or read so weird? Does this person just write like this? Is this a person at all?
I imagine there are some people who do not much care if the news article they are reading or the music they are listening to was generated by A.I. — with or without their knowledge. I think it feels cheap and shameful. There are interesting uses for generating material based on known patterns and structures but we are stuck with a bunch of spam, and it makes everything feel inherently suspicious. Perhaps that is in some way a good thing; we should be more careful, in general. I think Koebler captures the feeling of being on constant high alert, and living in an increasingly artificial and scam-filled world.


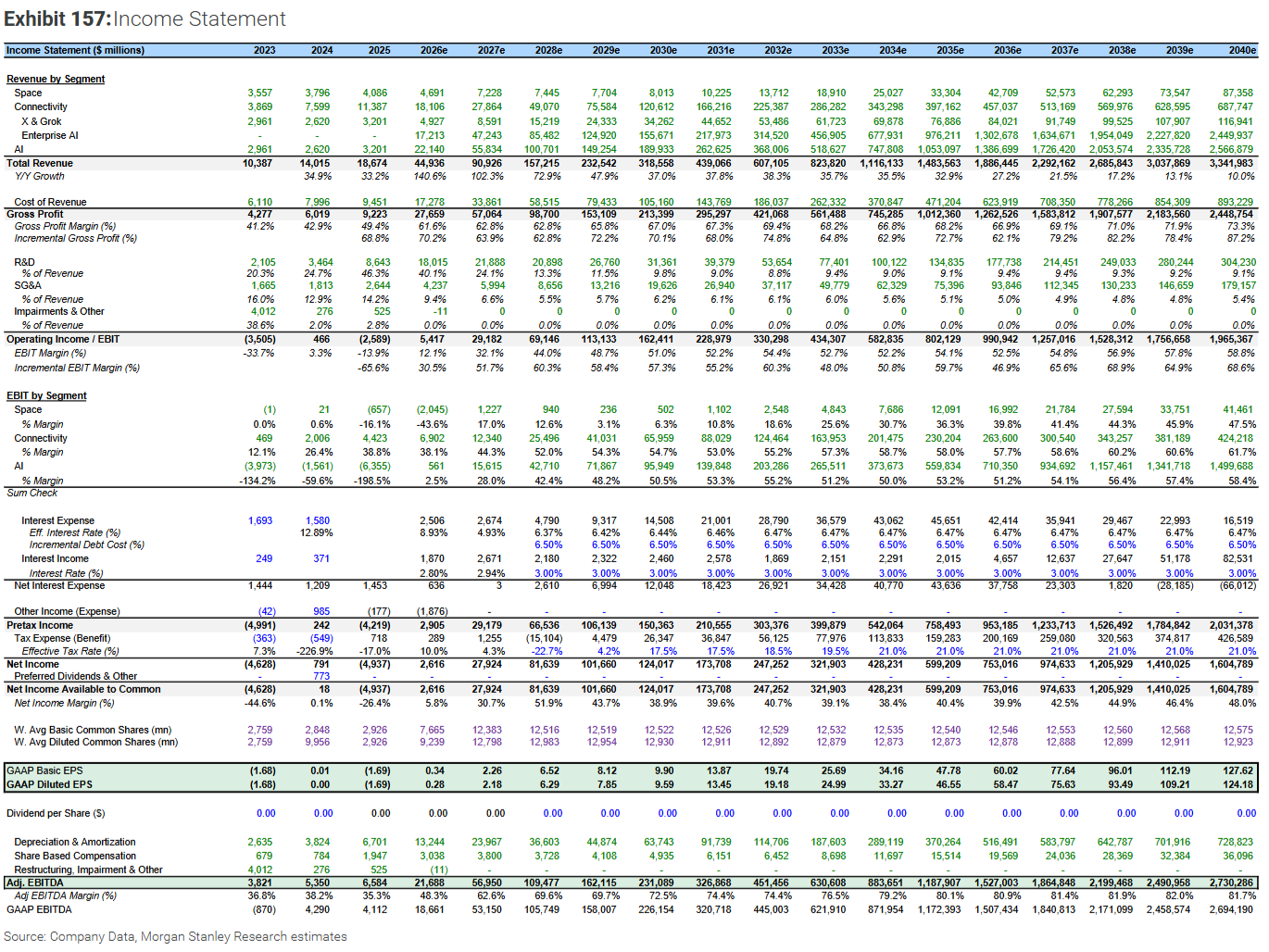{kind=link}
{kind=link}