Well, they got me. I am now paying for YouTube.
For years, I have used an ad blocker only infrequently on YouTube partly because the ads used to be short and not too disruptive, but mostly because I feel bad for people who make videos for a living. There is basically no alternative to YouTube.
Text is small; I can take this website anywhere I want. I can make my writing as discoverable or as paywalled as I deem makes sense. The same is true, to varying degrees, for images and audio. If someone does not like how their podcast host is behaving, they can move their show. It is not easy but it is doable.
That is not the case for video — at least, not for independent makers in the safe-for-work realm. You might use any number of streaming apps for video from large studios, and perhaps smaller ones too, like Dropout and Nebula. But there is no second YouTube. Even though TikTok and Instagram provide sufficient competition in the mobile short-form format, there is simply nothing else for longer formats in landscape. Sites like Dailymotion are doing so poorly they are deleting videos if they have no activity for about a year. Video makers on alternative sites like Rumble still post clips or copies of their show to YouTube; despite their persistent whining about alleged censorship, their videos are not removed from YouTube, and they know it remains the best platform for discovery.
I began considering a YouTube Premium subscription a couple of years ago when the great Alec Watson mentioned that creators like him get a cut. Which, in hindsight, seems obvious: instead of ad revenue, they get a portion of subscription revenue. But this was and remains unmentioned in YouTube’s marketing. Call it parasocial, non-derogatory, but this is the most compelling argument for why I should pay for YouTube. I support several indies through Patreon, too, but this means I get to be even more supportive without making specific monthly commitments, and I get a better experience.
The experience, by the way, is what pushed me over the edge. Remember how I mentioned “ads used to be short and not too disruptive”? Over the past few years, YouTube has increased the default ad load and duration. Before I had Premium, I was seeing ads every one or two minutes in many videos where the uploader had not changed the ad settings. Being that intrusive is something only YouTube can do because, again, it has no competition.
The process for actually paying for YouTube was bizarrely difficult. Since I already have a music streaming subscription, the Premium Lite option was a good fit for me. However, Google simply would not geolocate me or my personal Google account to Canada, where the Lite option is available. There was no way to correct Google’s assumption about where I was located; it simply did not let me see the Lite registration page, even though the currency was displayed in Canadian dollars.
So I made a new account in my Google Workspace dashboard just for YouTube. It turns out this was a little complicated, too, as I now needed to enable various Google services to make this work: YouTube and Google Pay, at first, and more later.
Then I used Safari’s autocomplete to enter my credit card details, which is where things got real weird. My card’s expiration date and CSC were entered correctly. The number itself was, too, until the last digit, at which point it abruptly changed to something completely different in nearly the same format — instead of four groups of four numbers, it became three groups of four, followed by one group of three. A test card number also encountered the same issue. Today, about a week later, I cannot reproduce it, so it seems like it has been fixed — but, still, strange.
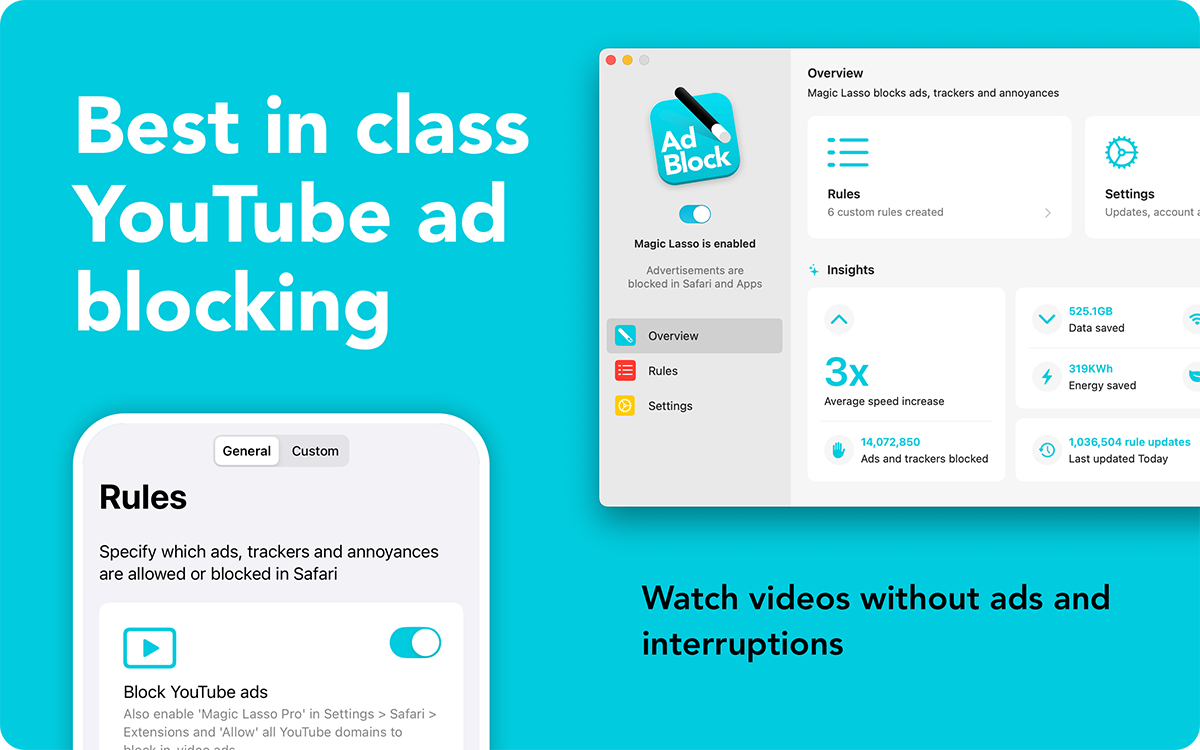
One unfortunate side effect of having a YouTube Premium membership is that I now need to sign into YouTube, which means I am also signed into all Google services. Because I am using a Workspace-type Google account, I have also needed to enabled additional services on the account, like Google Maps. I can work around this by using YouTube in a separate browser and configuring Safari to open all YouTube links in that other browser — but that is not a great experience. I have as much tracking turned off as I am able through Google’s settings, plus Safari has generally better tracking protection. And I really do use frequent site sponsor Magic Lasso Adblock, which truly helps me avoid a bunch of tracking I see in the wild; the difference is obvious in Web Inspector if I refresh a page without having Magic Lasso enabled.
I am still seeing the occasional ad on YouTube on videos where they should not be present. In general, however, this is a night-and-day experience. YouTube has successfully degraded its free experience to the point where it feels like the trial version of paid software. A single meaningful competitor would be a corrective force. Alas, only YouTube is YouTube, and that makes things worse for audiences and video makers alike.